In early 2024, Flyhomes published 425,000 pages in under three months and watched their organic traffic jump from 18,700 to 2,000,000 monthly visits—a +10,737% increase. An AI image generator SaaS built 15,000 landing pages in 90 days and grew monthly signups from 67 to 2,100+. These are not anomalies. They are the product of a repeatable, code-driven playbook called programmatic SEO—and AI coding assistants like Claude Code have made that playbook accessible to solo developers for the first time.
This guide walks through the complete workflow: how to cluster keywords at scale, build generation pipelines that pass Google's quality bar, implement every technical SEO element with real code patterns, and avoid the traps that got G2 and hundreds of other sites penalized. Every section includes concrete code you can run today.
Part 1: The Programmatic SEO Foundation
What programmatic SEO actually is
Programmatic SEO generates large numbers of search-optimized pages by combining a consistent page template with structured data. The foundational formula is simple: head term + modifier = page. "Best restaurants in [city]." "USD to [currency] converter." "[App A] + [App B] integration." Each page is distinct only in its variable data; the template handles layout, navigation, schema markup, and CTAs.
Once the template and data pipeline are in place, the marginal cost of creating page N+1 approaches zero. That asymmetry—high setup cost, near-zero per-page cost—is what makes programmatic SEO so powerful for businesses sitting on structured data.
As Ahrefs explains, pSEO differs from traditional content in that you're not writing individual pages—you're writing a template and a data layer, then letting the system do the rest.
When it works—and when it does not
Programmatic SEO performs best when all of these are true:
A scalable keyword pattern exists with 100+ viable permutations
Structured, differentiated data exists per page (not just a swapped variable)
Search intent is transactional, navigational, or lookup-based
The site has sufficient domain authority for crawl budget
Grow your organic traffic from chat-bots
Track your AI visibility across ChatGPT, Gemini, Claude, and Perplexity — and turn chat-bot mentions into traffic.
Free to start
No credit card required
Setup in 60 seconds
Keep reading
Related posts
More articles on the same topics, prioritized by shared tags and keyword overlap.
It consistently underperforms for informational queries where Google's SERPs reward long-form editorial content—how-to guides, opinion pieces, deep comparisons. If the top 10 results for a query are all 3,000-word guides, a data-driven template page will not outrank them regardless of data quality.
The data source hierarchy
Not all data sources are equal. The defensibility of your programmatic pages depends almost entirely on where your data comes from:
Tier
Source Type
Examples
Competitive Risk
1
Proprietary / user-generated
Airbnb listings, Glassdoor salaries, Yelp reviews
None — cannot be replicated
2
Licensed / API-sourced
Google Places API, MLS feeds, currency APIs
Low — widely available but legitimate
3
Publicly scraped
Wikipedia tables, government datasets
Medium — ToS questions; easily replicated
4
AI-generated filler
LLM-written "unique" paragraphs per location
High — scaled content abuse under Google 2024 policy
Google's March 2024 core update formally named scaled content abuse as a spam violation: "Generating many pages where the content is only slightly different, with the primary purpose of manipulating search rankings rather than helping users." Pages built on Tier 4 data are the highest-risk implementation. The practical threshold cited in Semrush's programmatic SEO guide is at least 60% distinct content across pages and 800–1,000 words of genuinely useful material.
The single rule that determines success
Each page must answer a specific user query in a way that cannot be replicated by simply changing a keyword in a template. Wise's currency pages work because they show live exchange rates. Canva's tool pages work because the page is the product. Flyhomes' city guides work because they're populated with real census and real estate data. The automation is in the infrastructure—not in faking uniqueness.
Part 2: Keyword Clustering at Scale with AI
Building the head term + modifier matrix
Start with 5–20 head terms drawn from your product's core use cases. Then enumerate modifiers across five dimensions: audience/use-case ("for accountants", "for startups"), location (city, region, country), comparison ("vs [alternative]"), attribute ("best", "free", "cheap"), and product variation (models, categories, SKUs). A single head term with three modifier dimensions can produce thousands of keyword candidates.
The SEOmatic keyword research guide recommends targeting keywords with 10–500 monthly searches, low difficulty scores, and minimum 3-word length. Seed expansion tools: Google Autocomplete, People Also Ask (via AlsoAsked), and Ahrefs/Semrush keyword ideas exports. From 10–20 seeds you should be able to reach 1,000–50,000 raw candidates.
Three clustering methods: when to use each
Method
Accuracy
API Cost
Best For
SERP-overlap
Highest
High (SerpAPI/DataForSEO per query)
Under 2,000 keywords
Embedding-based HDBSCAN
High
Low (local model = free)
Over 2,000 keywords
Hybrid
Highest at scale
Medium
Large sets needing fine-grained splits
SERP-overlap clustering (best accuracy): if two keywords share 40%+ of their top-15 ranking URLs weighted by position, Google already treats them as the same intent—so they belong in the same cluster. As Search Engine Journal's Python tutorial shows, this approach requires no NLP model and is robust because Google's ranking already encodes intent. It is API-cost-heavy, so it is practical only at smaller scale.
Embedding-based HDBSCAN clustering (best for scale): generate dense vector embeddings for every keyword using the open-source all-MiniLM-L6-v2 model from sentence-transformers (runs locally, free). Then cluster with HDBSCAN, which auto-discovers the cluster count and handles noise without requiring you to specify K upfront. Finally, use Claude API in batch mode to auto-label each cluster with a descriptive name. At 50,000 keywords, this pipeline runs in under two minutes.
The embedding + clustering pipeline with Claude Code
Claude Code can write this entire pipeline in a single session. Hand it this prompt:
"Write a Python script that:
1. Takes a CSV of keywords (keyword, monthly_volume columns)
2. Generates sentence-transformer embeddings using all-MiniLM-L6-v2
3. Clusters with HDBSCAN (min_cluster_size=5, min_samples=3)
4. Calls the Claude API to auto-label each cluster with a 4-5 word topic name
5. Outputs a CSV with keyword, cluster_id, cluster_label, intent_type columns"
The output script will look roughly like this:
from sentence_transformers import SentenceTransformer
import hdbscan
import pandas as pd
import anthropic
import json
def cluster_keywords(csv_path: str, output_path: str) -> pd.DataFrame:
df = pd.read_csv(csv_path)
keywords = df["keyword"].tolist()
# Embed
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(keywords, show_progress_bar=True)
# Cluster
clusterer = hdbscan.HDBSCAN(min_cluster_size=5, min_samples=3)
df["cluster_id"] = clusterer.fit_predict(embeddings)
# Auto-label each cluster with Claude
client = anthropic.Anthropic()
labels = {}
for cid in df["cluster_id"].unique():
if cid == -1:
labels[cid] = "Unclustered"
continue
sample = df[df["cluster_id"] == cid]["keyword"].head(20).tolist()
msg = client.messages.create(
model="claude-opus-4-7",
max_tokens=100,
messages=[{
"role": "user",
"content": f"Summarize these search keywords in a 4-5 word topic: {sample}"
}]
)
labels[cid] = msg.content[0].text.strip()
df["cluster_label"] = df["cluster_id"].map(labels)
df.to_csv(output_path, index=False)
return df
cluster_keywords("keywords.csv", "clusters.csv")
```
From clusters to page architecture
Once clustered, map each group to a template type:
[City] + [Service] clusters → local landing page template
[Product] vs [Alternative] clusters → comparison page template
[Tool] for [Role/Industry] clusters → use-case landing page template
As GrackerAI's clustering guide notes, the cluster-to-template mapping also determines your URL structure (/service/location/), internal linking topology, and build priority. High-volume, low-difficulty clusters go first.
Part 3: Building the Generation Pipeline with Claude Code
Pattern A: One-shot technical SEO handoff
The fastest Claude Code win for developers is a single-session full technical SEO implementation. One documented Next.js case shows what a single prompt can accomplish. The prompt was simply: "Analyze my Next.js website and add comprehensive SEO optimization — meta tags, sitemap, robots.txt, structured data, Open Graph tags, and canonical URLs for all pages."
Claude Code wrote: generateMetadata functions across all routes, app/sitemap.ts (auto-regenerating from routes including 7 language locales), app/robots.ts, a reusable StructuredData.tsx component, and hreflang/canonical logic. Result: 120+ pages indexed across 7 locales within 48 hours. Source: Medium — I Used Claude Code to Add SEO to My Next.js Site.
Ryan Law, Ahrefs' Director of Content Marketing, built a 23-skill pipeline behind a master blog-pipeline orchestrator that runs keyword research → topic gap analysis → structural outlining → drafting → formatting, producing publish-ready articles in 6–12 minutes.
Each Claude Code skill file contains three elements: markdown-formatted process instructions, best-practice examples to emulate, and formatting expectations for outputs. The critical dependency is live data. As Law notes: "LLMs are very convincing bloviators" without grounded real-time keyword metrics. His pipeline uses the Ahrefs MCP to inject live SERP data at every stage. Source: Ahrefs — How I Do Content Engineering with Claude Code.
This architecture is directly applicable to programmatic SEO: instead of a blog-pipeline skill, you build a pseo-pipeline skill that chains keyword → cluster → template → generate → validate.
Pattern C: Generation pipeline with quality validation
The most complete pSEO pipeline documented uses Claude Code to write the generation infrastructure, and the Claude API to do the per-entity generation. Entity data arrives as JSON; the prompt instructs Claude to produce content grounded exclusively in that data. As CC for SEO's guide documents, the critical constraint is:
"Do not add content not grounded in the entity data provided"
This single instruction prevents the fabricated local details that trigger quality penalties. The pipeline also includes a validation layer that runs after each batch:
import hashlib
from anthropic import Anthropic
client = Anthropic()
def validate_generated_page(entity_data: dict, content: str) -> dict:
# 1. Duplicate detection via MD5 fingerprint
fingerprint = hashlib.md5(content.encode()).hexdigest()
# 2. Minimum word count check
word_count = len(content.split())
if word_count < 800:
return {"valid": False, "reason": f"Too short: {word_count} words"}
# 3. JSON-LD schema validation
if '"@context": "https://schema.org"' not in content:
return {"valid": False, "reason": "Missing JSON-LD schema"}
# 4. Key entity field presence check
for field in ["city", "service"]:
if entity_data.get(field) and entity_data[field] not in content:
return {"valid": False, "reason": f"Missing entity field: {field}"}
return {"valid": True, "fingerprint": fingerprint}
Pattern D: Modular skill system (12-skill pSEO)
The most sophisticated open approach, documented by Mari Luukkainen, is a skills-based architecture compatible with Claude Code (.claude/skills/), Cursor (.cursor/rules/), GitHub Copilot (.github/copilot-instructions.md), and Windsurf. The four core pSEO skills are:
pseo-discovery — analyzes an existing codebase to identify which entity types are worth building pages for
pseo-audit — validates data sufficiency before generation starts (minimum fields, data freshness, uniqueness score)
pseo-data — designs the data layer schema and seeding pipeline
pseo-quality-guard — post-generation validation with MinHash/LSH near-duplicate detection to prevent thin-content penalties
The MinHash/LSH step is particularly important: it catches cases where two generated pages are semantically near-identical even if their MD5 fingerprints differ, which is the pattern Google's scaled content abuse detection is specifically looking for.
Pattern E: SEO data analysis hub
For teams who already have SEO data but struggle to synthesize it, Claude Code inside Cursor provides a powerful analysis layer. Python fetchers pull Google Search Console, GA4, and Google Ads data into local JSON files. Claude Code then answers cross-source questions in seconds. As Search Engine Land documents, one higher-education client analysis identified 2,742 wasted ad-spend keywords and 41 content gaps in 90 seconds—work that previously took analysts hours.
Part 4: Technical SEO Automation — The Code Patterns
Schema markup at scale
JSON-LD is Google's preferred format for structured data and the right choice for programmatic pages because it decouples markup from HTML structure. In Next.js App Router, schema is injected directly into the page component. Here's the official Next.js pattern:
The .replace(/</g, "\u003c") is a required XSS mitigation—never omit it. For TypeScript type safety, install the schema-dts package, which provides typed interfaces for every Schema.org type and catches invalid fields at compile time.
The schema types most commonly generated programmatically, with their primary use cases:
Schema Type
Use Case
Key Fields
FAQPage
Captures PAA features; content Q&A pages
mainEntity → Question + acceptedAnswer
LocalBusiness
Location-based programmatic pages
name, address, geo, openingHours
Product
E-commerce, SaaS pricing pages
name, offers (Offer type), aggregateRating
Article / BlogPosting
Editorial, blog content
headline, author, datePublished, publisher
SoftwareApplication
SaaS tool landing pages
name, applicationCategory, offers
Claude Code's role in schema automation: infer the correct schema type from page content, generate conditional field inclusion logic (e.g., only add aggregateRating when review data exists), and keep CMS field mappings synced so when a CMS field changes the schema updates automatically.
Internal linking automation
Internal linking is not optional for programmatic sites—it is the primary discovery mechanism for crawlers at scale. The GrackerAI internal linking guide recommends TF-IDF cosine similarity for finding link candidates automatically:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def find_link_candidates(
source_content: str,
all_pages: list[str],
threshold: float = 0.6
) -> list[tuple[int, float]]:
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform([source_content] + all_pages)
similarities = cosine_similarity(tfidf_matrix[0:1], tfidf_matrix[1:])
candidates = [
(i, score)
for i, score in enumerate(similarities[0])
if score >= threshold
]
return sorted(candidates, key=lambda x: x[1], reverse=True)
Standard link structure per programmatic page: (1) always link up to the parent category page, (2) link to 2–3 sibling pages in the same category, (3) link to 1–2 topically related pages in other categories. For anchor text: generate semantic variations with AI rather than repeating exact-match keywords—"securing your cloud infrastructure" instead of "cloud computing security" every time.
Meta tags at scale: generateMetadata
Next.js App Router's generateMetadata function is the canonical pattern for dynamic meta tags. It runs as a Server Component, so you can call the database directly with no client-side cost:
// app/[city]/[service]/page.tsx
import type { Metadata } from "next"
export async function generateMetadata({ params }): Promise<Metadata> {
const { city, service } = await params
const data = await fetchPageData(city, service)
return {
title: `${data.service} in ${data.city} | YourBrand`,
description: `Find the best ${data.service} in ${data.city}. ${data.tagline}`,
alternates: {
canonical: `https://yoursite.com/${city}/${service}`,
},
openGraph: {
title: `${data.service} in ${data.city}`,
description: data.tagline,
images: [data.ogImage],
},
}
}
// Root layout (app/layout.tsx) — applies brand suffix automatically
export const metadata: Metadata = {
title: {
template: "%s | YourBrand",
default: "YourBrand",
},
metadataBase: new URL("https://yoursite.com"),
}
Always set alternates.canonical on every programmatic page. Without it, Google may treat variations of the same page as duplicates and consolidate them—collapsing your programmatic pages into a single indexed URL.
// app/products/sitemap.ts
export async function generateSitemaps() {
// Returns one entry per sitemap shard needed
const count = await db.count("SELECT COUNT(*) FROM products")
const shards = Math.ceil(count / 50000)
return Array.from({ length: shards }, (_, i) => ({ id: i }))
}
export default async function sitemap({ id }): Promise<MetadataRoute.Sitemap> {
const start = id * 50000
const products = await db.query(
`SELECT slug, updated_at FROM products LIMIT 50000 OFFSET ${start}`
)
return products.map(p => ({
url: `https://yoursite.com/products/${p.slug}`,
lastModified: p.updated_at,
changeFrequency: "weekly" as const,
priority: 0.7,
}))
}
This generates sitemap shards at /products/sitemap/0.xml, /products/sitemap/1.xml, etc. The key advantage: because the sitemap queries the same database as the pages, it stays in sync automatically. No separate sitemap management step.
Part 5: Real Results from Programmatic SEO
The research here covers six documented cases, ranging from early-stage SaaS to large established platforms.
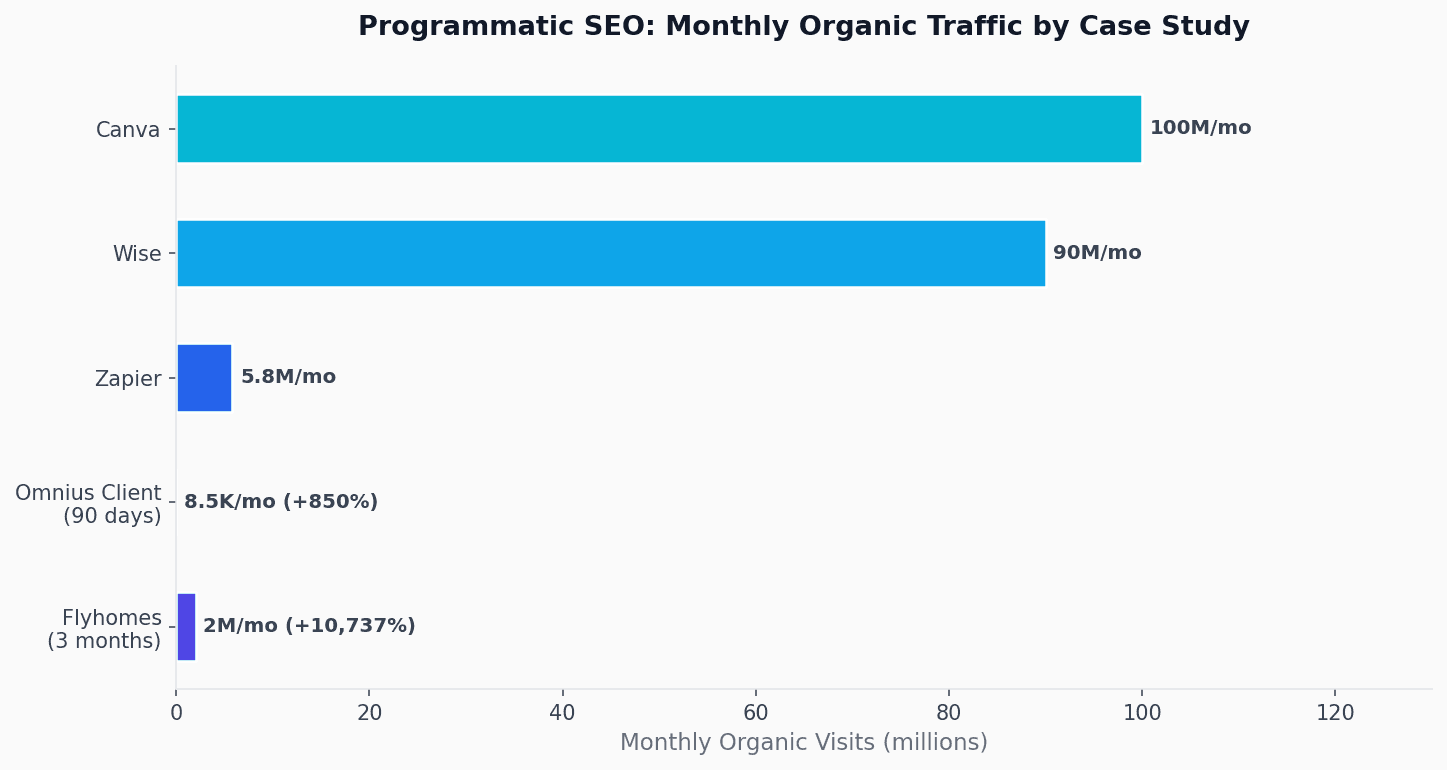
Figure 1: Monthly organic traffic by programmatic SEO case study
Flyhomes — 425,000 pages, +10,737% in 3 months
Flyhomes published 425,000+ city guide pages covering Cost of Living, Neighborhood Guides, Housing Market Analyses, and Quality of Life data. AIOSEO's case study documents the full arc: traffic went from 18,700 to 2,000,000 monthly visits in three months. Cost of Living Guides alone accounted for 55.5% of all site traffic. What made it work: real census and real estate data per city, question-based subheadings optimized for Google's People Also Ask feature, and 301 redirects from a domain acquisition channeling existing authority.
Wise — 90M monthly visits from currency and routing pages
Wise built two programmatic families at massive scale: millions of live currency pair pages ("USD to INR Today") and bank routing number pages (one per bank/state combination). Their 90M+ monthly organic visits come from the fact that every page is a functional tool—it shows the live exchange rate, completes the conversion, and provides supporting context. The programmatic page is not a marketing page about a tool; it is the tool.
Canva — 190,000 pages, 100M+ monthly visitors
Canva built ~190,000 pages across three families: "Free {Tool} Maker" pages, "{Format} Templates" collections, and industry/role verticals. Their 100M+ monthly organic traffic results from the same principle as Wise: the Logo Maker page (179K/month) is not an SEO page about the logo maker—it is the logo maker. The programmatic page is the product.
Omnius Client — 15,000 pages, signups +3,035% in 90 days
An AI image generator SaaS built 15,000+ landing pages in under 90 days using a keyword matrix from Google Autocomplete, PAA data, and competitor indexed pages. The technical stack was practical and accessible: Google Sheets → WordPress + Advanced Custom Fields + WP All Import for batch CSV-to-page publishing. Results from Omnius: monthly organic clicks grew from 102 to 8,500 (+850%), and monthly signups grew from 67 to 2,100+ (+3,035%).
Cautionary tales: what gets penalized
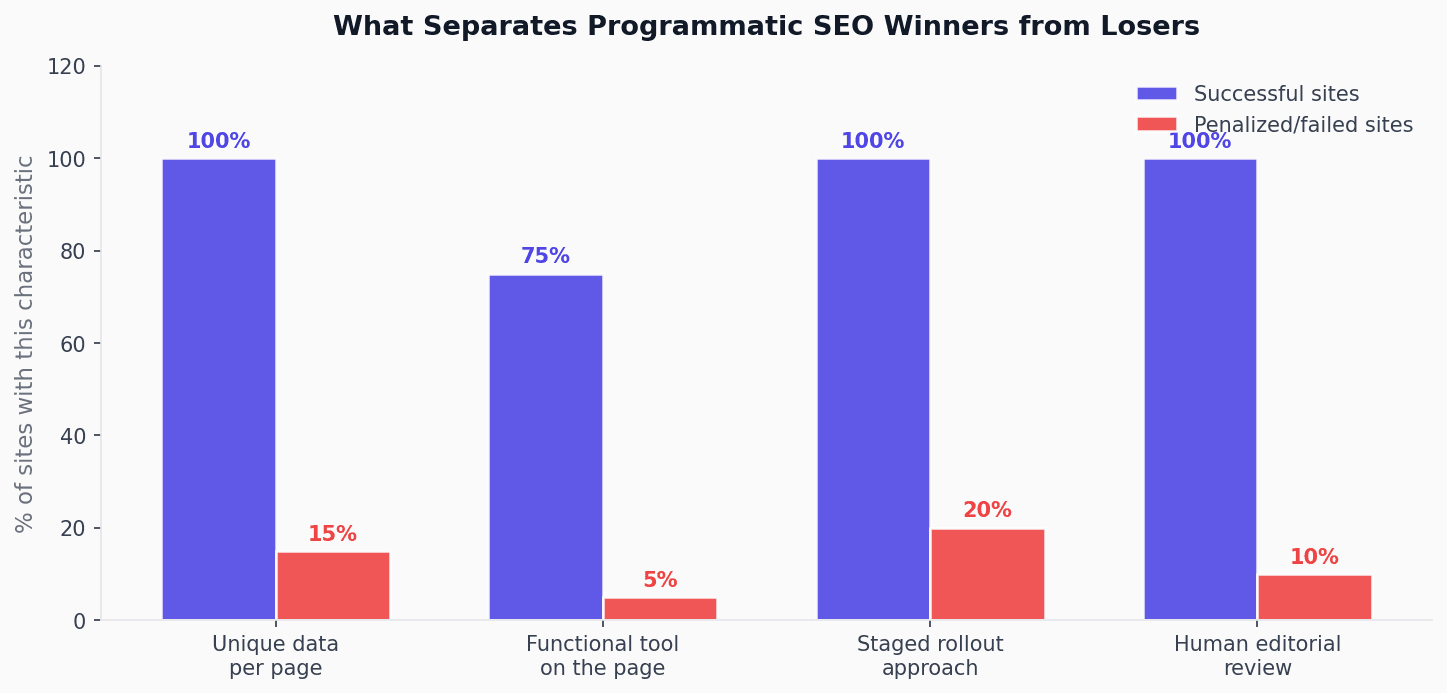
Figure 2: Key characteristics that separate successful pSEO sites from penalized ones
G2's programmatic category pages lost 85% of their traffic following 2023–2026 core updates. The problem: content appeared ghostwritten by authors who hadn't actually used the software they reviewed. Location-page farms ("Plumber in [City]" replicated 5,000 times with identical body text) lost 30–60% of traffic in the March 2026 core update. Sites publishing 50–500 AI-generated articles per day without editorial review lost 60–80% of traffic.
The pattern across all failures is the same: automation of keyword swapping without automation of unique value. Google is not penalizing programmatic SEO as a technique. It is penalizing pages that provide nothing unique beyond the changed keyword variable. The winners survived because their data, tools, or unique content genuinely served users who landed on those pages.
Part 6: The Staged Rollout Strategy
Why you cannot launch 50,000 pages at once
Google allocates a crawl budget per domain. Launching tens of thousands of pages on a young domain means most will sit in "Discovered – not currently crawled" limbo for months. As Positional's programmatic SEO guide notes, "higher-authority websites can often get away with a lot more"—but even established domains should not spike pages without monitoring.
The correct sequence:
Editorial foundation first. Publish 20–30 high-quality editorial posts to establish topical authority and domain trust. This also gives Google a positive signal about content quality before you scale.
Initial batch of 200–500 programmatic pages. Monitor Google Search Console for Index Coverage. Watch for the "Discovered – not currently crawled" status on your programmatic URL prefix—this is the warning sign.
Expand incrementally. As crawl stats confirm Google is processing new pages efficiently, increase batch size. Never launch more than you can monitor.
Ongoing maintenance. Stale data is an active liability at scale. Real estate prices, exchange rates, and business information change. Programmatic pages with wrong data erode user trust and increase bounce rates—damaging rankings sitewide.
What to monitor in Google Search Console
Index Coverage: "Discovered – not currently crawled" is your key warning signal
Crawl stats: pages crawled per day—track the trend after each batch launch
URL Inspection: spot-check individual programmatic pages for indexability and schema validity
Performance: track impressions-vs-clicks ratios for your programmatic URL prefix separately from editorial content
Use URL prefix filters in GSC to segment your programmatic pages from editorial content. A drop in click-through rate on programmatic pages often signals an intent mismatch that needs fixing at the template level, not individual page edits.
Conclusion
Programmatic SEO is not a shortcut to rankings—it is a system for serving users at scale. The sites that won big (Flyhomes, Wise, Canva, Omnius) all share the same property: their programmatic pages genuinely help users in ways that required real data or real tools, not just templated text.
Claude Code removes the engineering barrier that previously made pSEO accessible only to well-resourced teams. The keyword clustering pipeline, the generation infrastructure with validation, the generateMetadata patterns, the split sitemaps—a solo developer can build all of it in days with an AI coding assistant. The part Claude Code cannot automate is the judgment: knowing which intent to target, which data source is defensible, which template genuinely serves users.
The staged rollout discipline and ongoing quality monitoring are not optional additions. They are the difference between the Flyhomes result and the G2 result.
If you're building programmatic SEO, tracking your AI visibility matters as much as tracking search rankings. QuickSEO monitors your brand across ChatGPT, Claude, Gemini, and Perplexity alongside Google Search — so you can see where your pages are actually being cited. Try the free AI visibility audit →