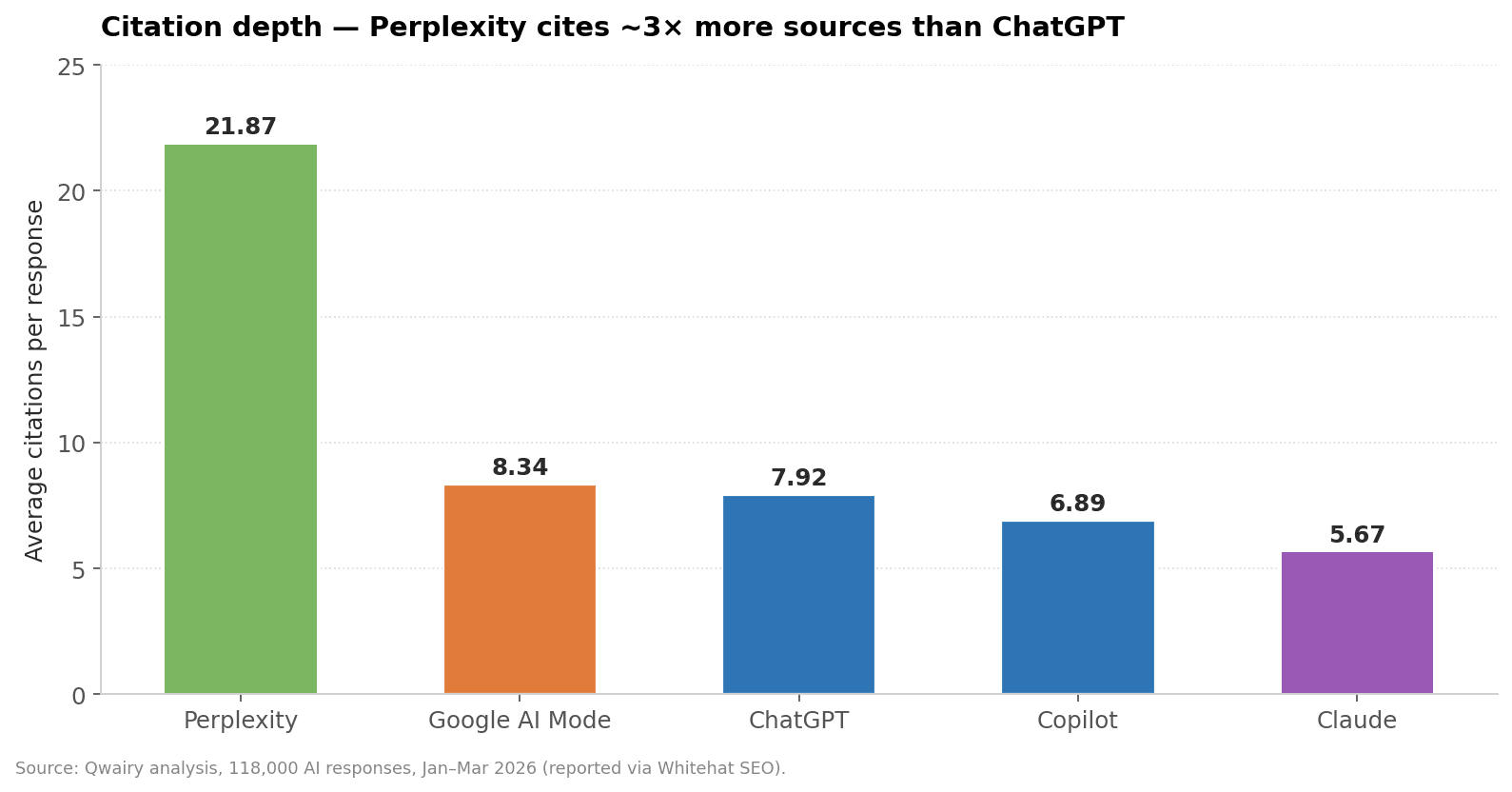Spotlight analyzed 1.8 million chatbot responses in February 2026 and found something marketers are still struggling to digest: Claude mentions a brand in 97.3% of answers, ChatGPT in 73.6%, and Google AI Overviews in just 48.5% (Spotlight, Tracking Brand Mentions in AI Chatbots).
In the same window, the gap in raw citation volume between the most generous chatbot (Grok) and the stingiest (Claude) — for a single tracked brand — was ~615×. And Claude, the platform that mentions brands more than any other, returned 0% positive sentiment on the same data set.
Three numbers, all real, none telling the same story. If you only remember one thing from this post, remember that "mention rate" hides at least three distinct metrics — and most published comparisons quietly conflate them. Below, the 2026 data, what each number actually measures, and what to do with it.
The three "mention rates" people mix up
Before any platform-by-platform comparison makes sense, separate three measurements that all get called "mention rate" in vendor marketing:
Metric
What it measures
Who reports it
Any-brand mention rate
Did the response contain a brand name — any brand — at all?
Spotlight (1.8M responses, Feb 2026)
Tracked-brand mention rate
Did the response contain your specific brand name?
Semrush AI Visibility / Kevin Indig (3,981 appearances)
Tracked-brand citation rate
Did the response link to your domain (regardless of naming)?
Profound, Superlines, Muck Rack, BrightEdge
Three metrics, three denominators. Mixing them is the single most common mistake in AI visibility benchmarking.
Conflating these is how you arrive at a Claude that's both the #1 most brand-verbose chatbot (Spotlight, 97.3% any-brand) and the #10 (Superlines, 0% tracked-brand). Both are true. Both measure different things on different samples. The rest of this post is organized by which question you're actually trying to answer.
How often does any brand appear at all?
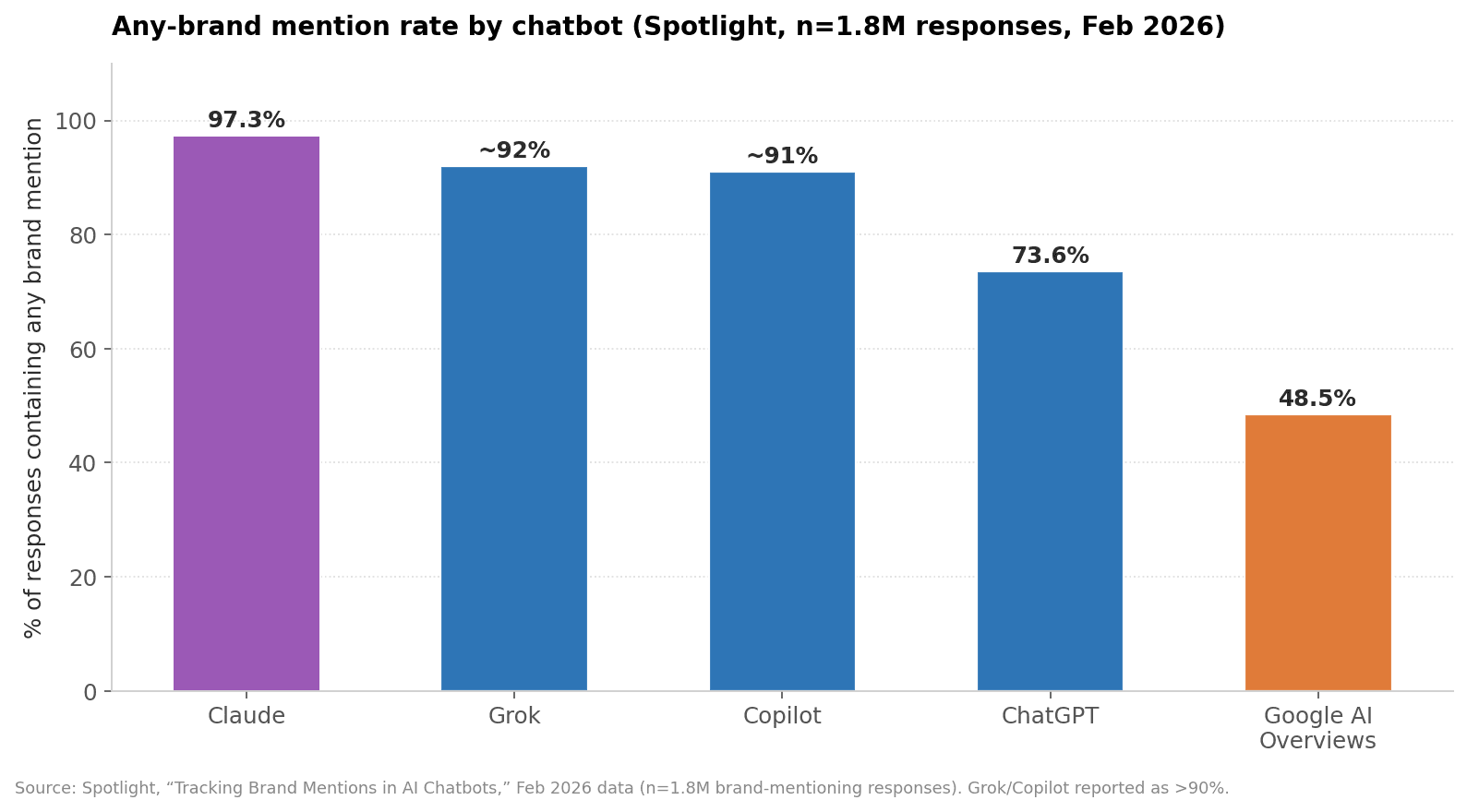
Spotlight's headline data set is 1.8 million brand-mentioning responses across the major chatbots in February 2026 (primary report). On that data set, the share of responses containing at least one brand name looks like this:
Any-brand mention rate by chatbot. Source: Spotlight, “Tracking Brand Mentions in AI Chatbots” (Feb 2026 data, n=1.8M responses). Grok and Copilot reported as >90% without an exact figure.
Claude: 97.3% — leads every other chatbot.
Grok: over 90%.
Copilot: over 90%.
ChatGPT: 73.6%.
Google AI Overviews: 48.5%.
Read this carefully: it measures LLM verbosity about brands as a category, not how often your brand appears. Claude's 97.3% says Claude is willing to name companies in almost every answer; it does not say Claude is willing to name you. The same study does not disclose prompt lists, brand lists, geos, or model versions, so it's best read as a vendor benchmark, not peer-reviewed research.
How often does YOUR brand appear?
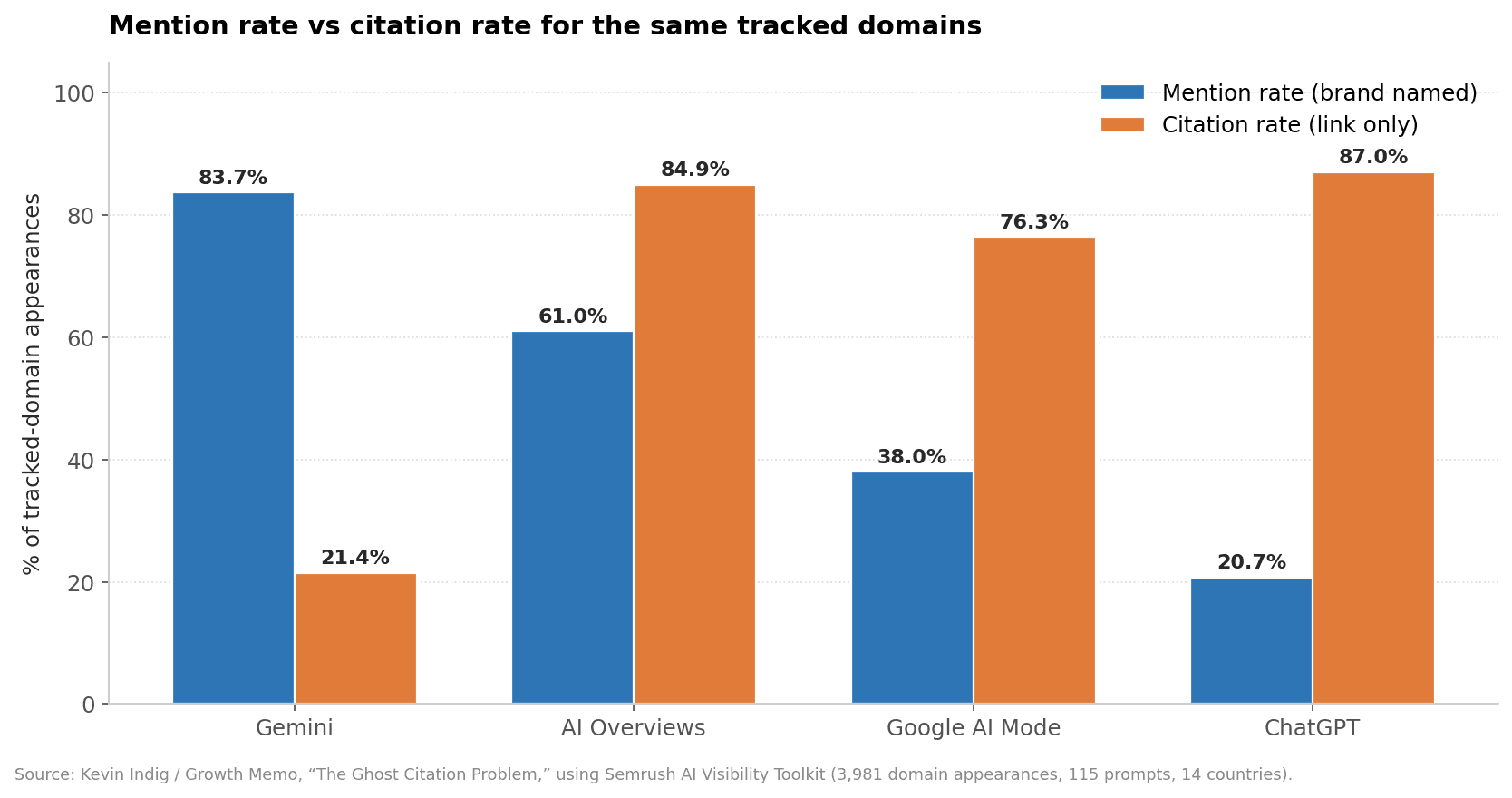
When the question is narrowed to a tracked domain, the picture flips. Kevin Indig's Ghost Citation Problem study — 3,981 tracked-domain appearances across 115 prompts in 14 countries, powered by the Semrush AI Visibility Toolkit — measures whether a tracked domain is named versus merely linked:
Mention rate vs citation rate for the same tracked domains. Source: Kevin Indig / Growth Memo, “The Ghost Citation Problem” (Semrush AI Visibility Toolkit, 3,981 appearances).
Gemini: 83.7% mention rate, only 21.4% citation rate — Gemini will say your name without linking you.
ChatGPT: 20.7% mention, 87.0% citation — ChatGPT will link you without saying your name.
AI Overviews: ~61% mention, 84.9% citation.
Google AI Mode: ~38% mention, 76.3% citation.
Aggregate the four engines and 61.7% of all citations are "ghost citations" — a link with no naming. The most striking single example from the same data: Gemini cited superlines.io 182 times in 30 days while saying the word "Superlines" zero times (Superlines AI Search Statistics 2026).
If you're already familiar with citation behavior at the domain level — what gets cited by ChatGPT, Claude, Gemini, and Perplexity covers the domain side of this picture in detail — this post is the brand-naming companion. The two questions "is my domain cited?" and "is my brand named?" are answered by completely different metrics.
The 615× citation gap, properly read
The 615× headline comes from Superlines' own tracking experiment (primary source) — 34,234 AI responses across 10 platforms over 30 days (Jan 14 – Feb 13, 2026), tracking the brand "Superlines" itself. The ratio between Grok's citation volume of superlines.io and Claude's came out to roughly 615 to 1.
Read the 615× stat correctly. It is not a universal industry multiplier. It is a single brand, over a 30-day window, on a specific prompt mix. Claude's 0 is partially a Claude-doesn't-link-by-default artifact, not Claude actively burying this brand. What the number really shows is that the spread of brand presence across platforms can be three orders of magnitude wide for the same brand at the same time — which is the actionable insight, not the precise multiplier.
Where does the brand land in the answer?
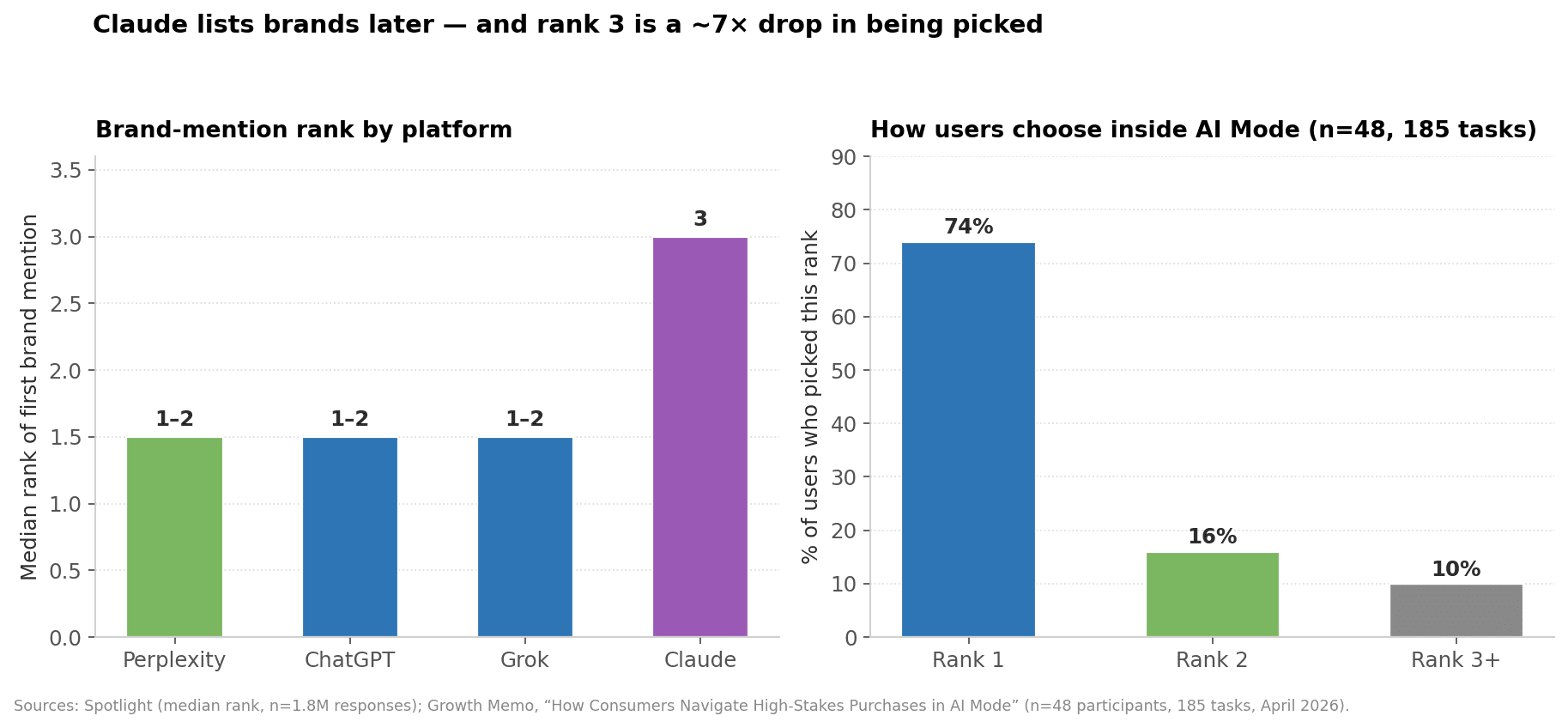
Even when a brand is mentioned, its rank inside the response matters. Spotlight reports the median rank of the brand's first appearance:
Perplexity, ChatGPT, Grok: median rank 1–2 (brand appears very early).
Claude: median rank 3 (other names appear before the brand).
That sounds minor until you cross-reference with Growth Memo's April 2026 usability study of 48 participants across 185 high-stakes purchase tasks in Google AI Mode (How Consumers Navigate High-Stakes Purchases in AI Mode):
74% of participants chose the brand ranked first in the AI's response.
Mean rank of final choice: 1.35.
Only ~10% picked a brand ranked 3 or lower.
88% of users picked from within the AI's shortlist on laptop and insurance tasks.
64% clicked nothing during the entire task — the AI's rank ordering was the decision.
Left: median rank of brand mention by platform (Spotlight). Right: how often AI Mode users picked each rank position (Growth Memo, n=48 participants, 185 tasks).
The implication for Claude is uncomfortable: Claude mentions brands more often than any other chatbot but tends to list them later. The rank-1 → rank-3 drop is roughly a 7× decline in being the user's final pick. A brand that ranks first on Perplexity and third on Claude can have a near-identical citation count and a completely different conversion outcome.
One caveat to remember: SparkToro reported in early 2026 that there is less than a 1-in-100 chance that ChatGPT or Google's AI returns the same brand list across 100 repeat queries (150+ AI SEO Statistics, Position Digital). Median rank is a smoothed aggregate, not a guarantee on any single prompt.
Linking behavior: the most contradictory metric in AI visibility
If you've read three different studies on "AI citation rate" and walked away confused, that is the correct reaction. Studies disagree by more than 90 points on the same platform. The reason: each measures a different denominator and (often) a different mode of the same chatbot. Three buckets:
Spotlight (Feb 2026, ~1.8M responses): Perplexity 96.5%, Copilot 77%+, ChatGPT ~50%, Claude 0% ("Claude does not link at all").
Muck Rack Generative Pulse (May 2026, 25M links, web search on): ChatGPT 96%, Gemini 82%, Claude 55% (Muck Rack report).
Superlines (Jan–Feb 2026, 34,234 responses, single tracked brand): Grok 27.01%, Perplexity 13.05%, ChatGPT 0.59%, Claude 0%.
Platform
Spotlight (any link)
Muck Rack (web search on)
Superlines (brand-domain)
Avg sources / answer (Qwairy)
Perplexity
96.5%
n/a
13.1%
21.87
ChatGPT
~50%
96%
0.59%
7.92
Gemini
n/a
82%
6.38%
—
Google AI Mode
n/a
n/a
9.09%
8.34
Copilot
77%+
n/a
1.27%
6.89
Grok
n/a
n/a
27.01%
—
Claude
0%
55%
0%
5.67
Five different studies, five different views of the same platforms. The metric mismatch — not platform behavior — explains most of the disagreement.
How to reconcile: Spotlight measures whether the user-facing UI surfaces a clickable link by default. Muck Rack measures whether a citable source is referenced when web search is enabled. Superlines measures whether a tracked brand domain specifically shows up as a link. All three are valid metrics; none are interchangeable.
The cross-source consensus, once you strip out methodology differences, is narrower than the headlines: Perplexity links the most consistently and the most deeply, Claude rarely surfaces inline links to end users by default, and ChatGPT sits in the middle and is the most measurement-sensitive of the bunch. For a head-to-head on the two platforms where the linking gap matters most for visibility, we compared Perplexity and ChatGPT for AI visibility — citations, traffic, and conversion in a separate post.
How deep is the citation list?
Among responses that do cite, the average number of sources varies sharply. Qwairy's analysis of 118,000 AI responses (Jan–Mar 2026, reported via Whitehat SEO):
Average citations per response. Source: Qwairy, 118K responses, Jan–Mar 2026 (via Whitehat SEO).
Perplexity: 21.87 citations per response.
Google AI Mode: 8.34.
ChatGPT: 7.92.
Copilot: 6.89.
Claude: 5.67.
Muck Rack's 25M-link pass gives a different Claude figure (an average of 13 citations per cited response — the deepest of any platform in that study). The reconciliation: when Claude cites, it can cite deeply, but its baseline citation surface is thinner than Perplexity's. BrightEdge's independent number for Perplexity (8.79 average, reported via Demand Local) is lower than Qwairy's but agrees directionally — Perplexity cites the most.
Across the same 1.8M brand-mentioning responses, Spotlight reports the aggregate sentiment split as 80.6% neutral, 18.4% positive, 1.0% negative — meaning positive mentions are about 18× more common than negative ones (the literal 18.4 ÷ 1.0 ratio).
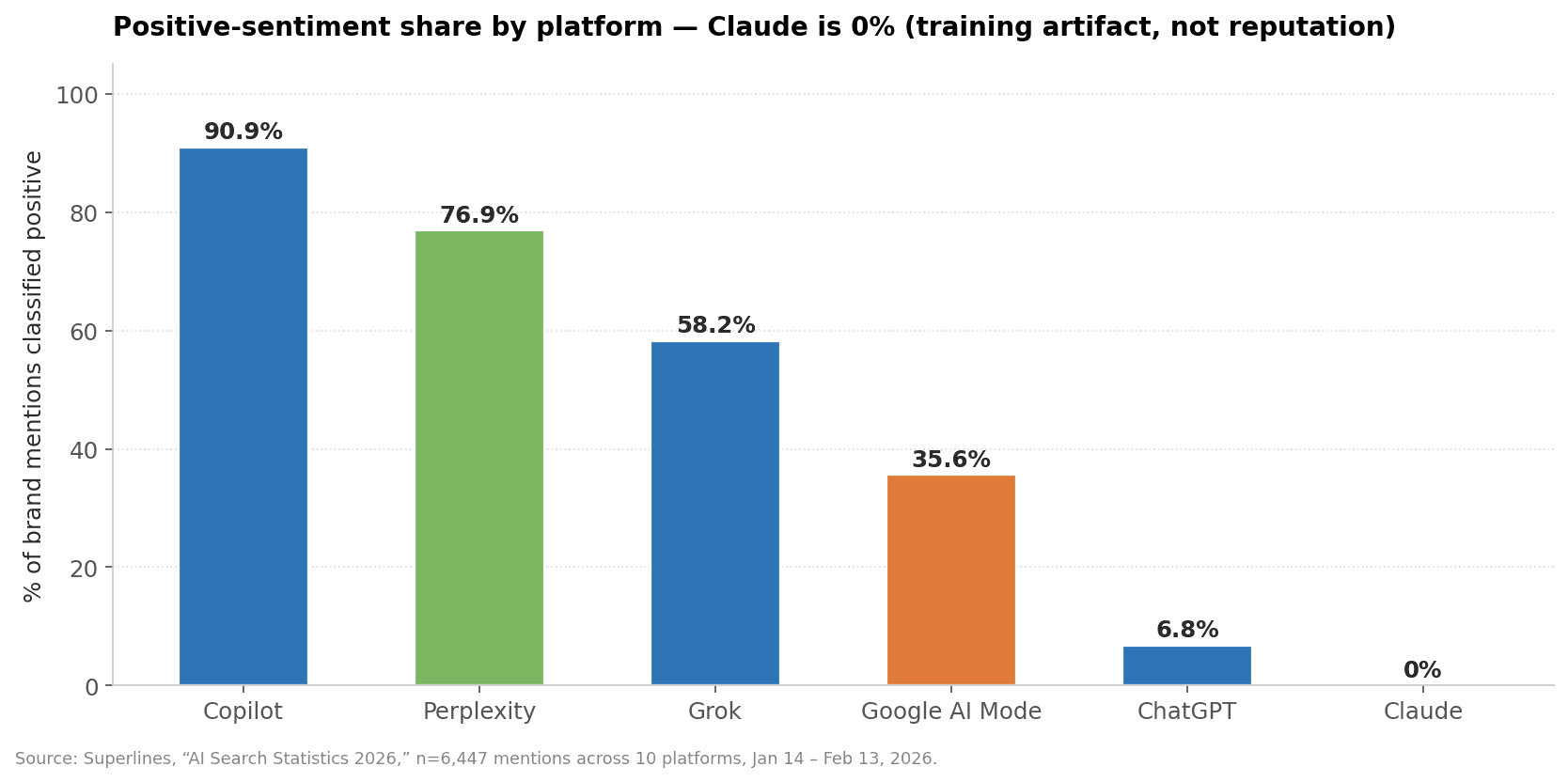
The platform-by-platform split is more interesting. Superlines reports the positive-sentiment share by platform across 6,447 mentions (Jan 14 – Feb 13, 2026):
Positive-sentiment share by platform. Source: Superlines, “AI Search Statistics 2026,” n=6,447 mentions, 10 platforms, Jan 14 – Feb 13, 2026.
Copilot: 90.9% positive — Bing's commerce-skewed index pulling through.
Perplexity: 76.9%.
Grok: 58.2%.
Google AI Mode: 35.6%.
ChatGPT: 6.8% positive — characterized as "neutral, rarely praises."
Claude: 0% positive.
Claude's 0% positive sentiment is the most-misread number in this entire data set. It is not Claude disliking brands; it is an artifact of Anthropic's training producing factual, zero-emotional prose. A brand that looks healthy on Perplexity (76.9% positive baseline) can look hostile on Claude (0% baseline) for the exact same content. Don't compare cross-platform sentiment scores directly. Benchmark within-platform.
A more useful sentiment taxonomy comes from Visiblie's 5-bucket framework, which breaks out endorsement (28%), neutral (41%), cautious (19%), and hallucination (12%) across 200+ brands. Binary positive/negative classifiers hide hedging, and hedging is where reputational risk actually lives. With an 80% neutral baseline, the goal of AI visibility work is to escape the neutral bucket at all, not to maximize positives — earning evaluative language is the rarer, more leveraged outcome.
What marketers should actually do
Five things the 2026 data actually supports. None of them is "chase the 97.3% number."
1. Pick the right metric for the question. "Are we mentioned?" (tracked-brand mention rate), "Are we cited?" (citation rate), and "Are we ranked first?" (median rank) are three different questions with three different metrics. Track all three; report them separately.
2. Don't average sentiment across platforms. A blended sentiment score is misleading the moment Claude is in the average. Benchmark within-platform, track the delta over time, and flag negative-share growth rather than absolute scores.
3. Optimize for rank, not raw mentions. In AI Mode, rank-1 brands win 74% of decisions and rank-3+ brands win ~10%. A 97% mention rate at rank 3 (Claude) is closer to "invisible" than to "dominant."
4. Hunt your ghost citations. 61.7% of all citations don't name the brand they link to. If Gemini is citing your domain 100+ times a month and never speaking your name, you have a naming problem on your most-cited pages — not a citation problem. Pages should reinforce the brand name in proximity to citable claims, statistics, and quotes.
5. Track weekly, not in snapshots. Vismore's data shows 38% of repeat prompts return meaningfully different brand lists (Vismore 750-response study). Single-point measurements are noise. A weekly trend line is signal.
If you're earlier in the discipline and want the conceptual grounding for these tactics, our guide to building AI visibility from the ground up walks through the foundational moves — content surfaces that get cited, structured-data signals that get parsed, and the metrics worth instrumenting before any of the per-platform optimization above pays off.
Close the measurement gap
The 2026 picture is consistent across every primary study we pulled: the brands that win in AI search instrument all three metrics — mention rate, citation rate, and rank — per platform, and treat each chatbot as its own discipline. The ones that lose treat "AI visibility" as a single number to chase.
QuickSEO tracks your brand presence across ChatGPT, Claude, Gemini, and Perplexity — mention rate, citation rate, rank position, and sentiment broken out per platform, alongside your Google Search data so you can see the AI and search halves of the funnel side by side. Run a free AI visibility audit on your domain and see what each chatbot is currently saying about your category.
Grow your organic traffic from chat-bots
Track your AI visibility across ChatGPT, Gemini, Claude, and Perplexity — and turn chat-bot mentions into traffic.
Free to start
No credit card required
Setup in 60 seconds
Keep reading
Related posts
More articles on the same topics, prioritized by shared tags and keyword overlap.