AI bots accounted for 4.2% of all HTML requests across Cloudflare's network in 2025, peaking at 6.4% in late June — and AI traffic grew 187% in a single year. Meanwhile, only one of the major AI crawlers — Googlebot — actually executes JavaScript. The others (GPTBot, ClaudeBot, PerplexityBot, Bytespider) fetch your pages but never run a line of your code.
If your mental model of crawlers still starts and ends with Googlebot, it's already obsolete. There are 30+ AI bots active on the open web in 2026, falling into three operationally different categories. Each demands a different robots.txt rule, and each rewards different optimizations.
This guide is the technical and practical map. By the end, you'll know exactly which bots are hitting your site, what they want, how to allow the ones that drive traffic and block the ones that don't, and how to structure content so AI engines actually cite you.
The three categories at a glance
Training crawlers — scrape the web to build foundation models. (GPTBot, ClaudeBot, CCBot, Bytespider, Meta-ExternalAgent)
Retrieval bots — fetch URLs in real time when an LLM needs to ground an answer. (OAI-SearchBot, Claude-SearchBot, PerplexityBot)
AI agents — autonomous browsers acting on behalf of a user. (ChatGPT Atlas, Perplexity Comet, Claude Computer Use)
Part 1: The Three Types of AI Crawlers
A single "block all AI" rule is now the wrong default. Each category does something different on your site, and each has a different impact on your business — so each deserves a different decision.
1.1 Training crawlers
Purpose: scrape the web to build training datasets for foundation models. They behave like classic spiders — breadth-first traversal, sitemap-driven, polite-ish.
Examples: GPTBot (OpenAI), ClaudeBot (Anthropic), CCBot (Common Crawl), Bytespider (ByteDance), Meta-ExternalAgent, Google-Extended (which is actually a control token, not a separate crawler), and Applebot-Extended.
Business implication: blocking these costs zero AI search visibility. The one nuance is CCBot, which feeds Common Crawl — many open-source models train on this dataset, so blocking it has indirect effects.
1.2 Retrieval / search bots
Purpose: fetch URLs in real time when an LLM needs to ground an answer or build a search index. They are bursty, query-driven, and often fetch the same authoritative pages repeatedly.
Business implication: these are the bots that drive citations and referral traffic. Block them and you go invisible in AI search. The default for most SMBs and publishers should be: allow.
1.3 AI agents (the new and growing category)
Purpose: autonomous browsing on behalf of a user — book a flight, fill out a form, compare prices, complete a checkout. Examples: ChatGPT Atlas / Agent (OpenAI), Perplexity Comet, Claude Computer Use, Google Project Mariner, and signed agents like Browserbase, Anchor, and Block's Goose.
Behavior: agents act like real browsers. Some now sign their requests with Web Bot Auth (HTTP Message Signatures, RFC 9421), which lets servers cryptographically verify the requester. ChatGPT Agent already signs every request.
HUMAN Security observed a 6,900% increase in agentic browser traffic since July 2025, and agentic e-commerce surged 144.7% during Black Friday–Cyber Monday 2025. This is the fastest-growing category by percentage.
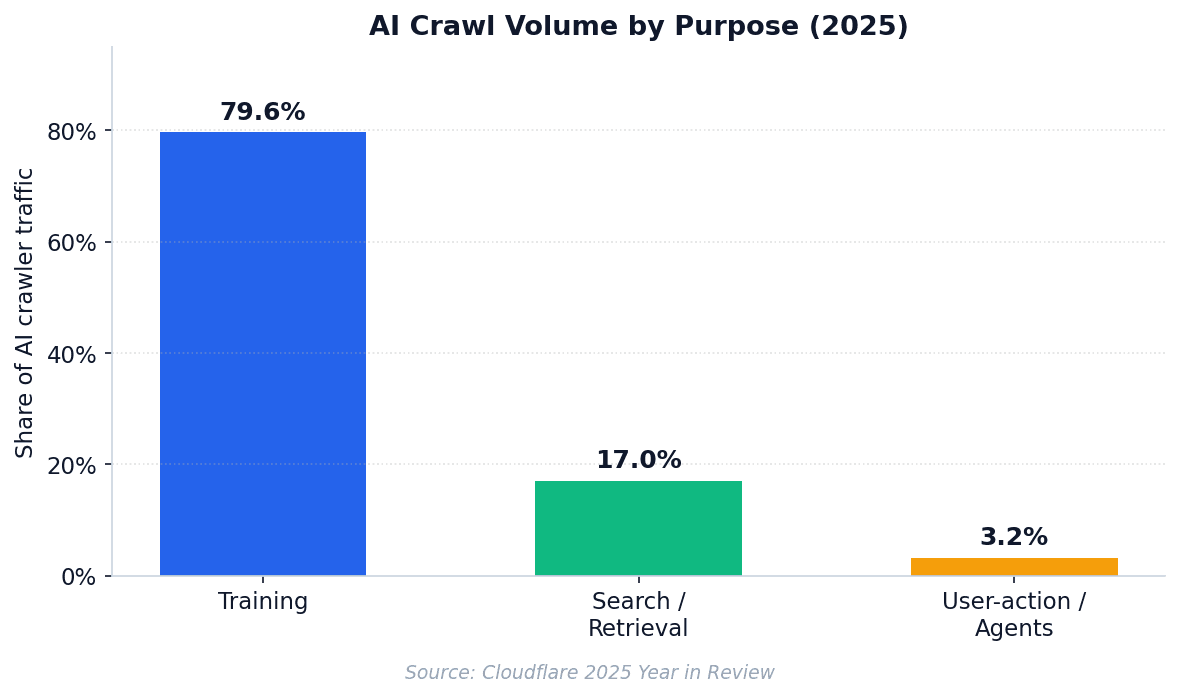
Training dominates AI crawler volume today, but user-action traffic grew >15× in 2025.
Part 2: The Complete AI Crawler Reference
Bookmark this section. Three tables — training crawlers, retrieval bots, and agents — covering every AI bot you'll likely see in your logs.
Training crawlers: complete reference list
Bot
Operator
User-agent token
Respects robots.txt?
GPTBot
OpenAI
GPTBot
Yes (verified)
ClaudeBot
Anthropic
ClaudeBot
Yes (per docs)
Google-Extended
Google
Google-Extended
Yes (control token; no Search impact)
Applebot-Extended
Apple
Applebot-Extended
Yes (control token only)
Bytespider
ByteDance / TikTok
Bytespider
No — documented violations
CCBot
Common Crawl
CCBot
Yes
Meta-ExternalAgent
Meta
meta-externalagent
Yes
FacebookBot
Meta
FacebookBot
Yes
Diffbot
Diffbot
Diffbot
Configurable
AI2Bot
Allen Institute
AI2Bot
Yes
cohere-ai
Cohere
cohere-ai
Yes
DeepSeekBot
DeepSeek
DeepSeekBot
Inconsistent
Retrieval / search bots: complete reference list
Bot
Operator
User-agent token
Drives citations?
OAI-SearchBot
OpenAI
OAI-SearchBot
Yes — ChatGPT Search index
ChatGPT-User
OpenAI
ChatGPT-User
Yes — user-initiated fetches
Claude-SearchBot
Anthropic
Claude-SearchBot
Yes — Claude search index
Claude-User
Anthropic
Claude-User
Yes — user-initiated fetches
PerplexityBot
Perplexity
PerplexityBot
Yes — index builder
Perplexity-User
Perplexity
Perplexity-User
Yes (may bypass robots.txt)
DuckAssistBot
DuckDuckGo
DuckAssistBot
Yes
Amazonbot
Amazon
Amazonbot
Yes — Search + Alexa
Google-CloudVertexBot
Google
Google-CloudVertexBot
Yes — Vertex grounding
MistralAI-User
Mistral
MistralAI-User
Yes
YouBot
You.com
YouBot
Yes
Bingbot
Microsoft
Bingbot
Dual-purpose: Bing + Copilot
AI agents (2025–2026): complete reference list
Agent
Operator
Detection method
Signs requests?
ChatGPT Atlas
OpenAI
Chrome 142 UA + 'ChatGPT Atlas' on favicon fetches
No
ChatGPT Agent
OpenAI
Web Bot Auth signature
Yes
Perplexity Comet
Perplexity
Chromium UA; internal extension visible in DOM
No
Claude Computer Use
Anthropic
API-driven; hard to distinguish from browser
No
Project Mariner
Google
Cloud-based VM (AI Ultra subscribers)
No
Browserbase / Anchor / Goose
Various
Web Bot Auth signature
Yes
Two things almost every blog post gets wrong
Google-Extended is NOT a separate crawler. It's a control token. Crawling is done by Googlebot. Same for Applebot-Extended.
ChatGPT Atlas is currently almost indistinguishable from Chrome. The only reliable identifier is a 'ChatGPT Atlas/.../CFNetwork/.../Darwin/...' substring sent only on favicon fetches.
Part 3: How AI Crawlers Actually Work
3.1 URL discovery
AI crawlers discover URLs the same way classic crawlers do: sitemaps, internal and external links, prior crawls, and Common Crawl seed lists. Retrieval bots additionally take URLs from upstream search engines — Bing for ChatGPT search, Brave for Claude search, an internal index for Perplexity.
3.2 Request patterns by category
Training: breadth-first, sitemap-driven, full traversal at low frequency.
Retrieval: query-bursty, narrow URL set per session, frequent revisits to authoritative pages.
User-action: tracks live human chat patterns. Cloudflare's 2025 data shows distinct weekday peaks and weekend dips for ChatGPT-User — a clear giveaway in your logs.
3.3 The JavaScript rendering gap
This is the single most important technical fact in this guide. Vercel analyzed billions of crawler requests across its customer base and found:
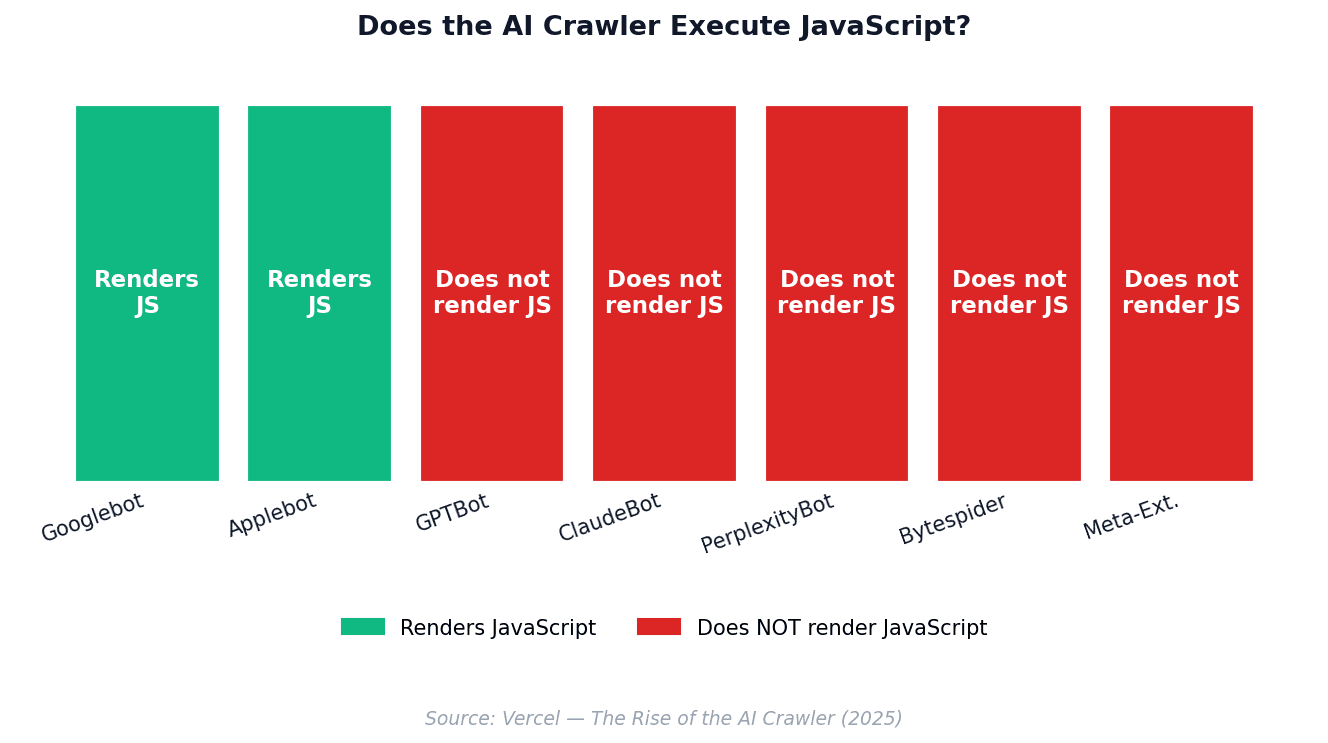
GPTBot, ClaudeBot, PerplexityBot, Bytespider, and Meta-ExternalAgent all fetch JavaScript files but never execute them. They download the .js file, count it as a request, and move on. Only Googlebot (and by extension Gemini's grounding) and Applebot render JavaScript.
ChatGPT crawlers spend 57.7% of fetches on HTML, 11.5% on JS files (downloaded but never run), and 31% on images, CSS, and other resources. Claude spends 35% of fetches on images and 23.8% on unexecuted JS. The 404 rate exceeds 34% for both — they request many URLs that no longer exist.
The implication is non-negotiable: if your site is a client-side-rendered SPA, ChatGPT and Claude see effectively nothing. Server-side rendering, static export, or pre-rendering is required for AI visibility.
Five of the seven major AI crawlers do not execute JavaScript. Server-side rendering is mandatory.
3.4 Retrieval-Augmented Generation: what happens after the fetch
A user asks the AI a question.
The LLM identifies candidate URLs via its own search index, an upstream search engine, or training data.
A retrieval bot fires HTTP fetches (ChatGPT-User, Claude-User, Perplexity-User) to those URLs.
Returned HTML is passed through a content extractor (boilerplate removal, semantic block detection).
Content is chunked (typical chunks: 200–1,000 tokens with 10–20% overlap), embedded, and either fed directly into the LLM context window or stored in a vector database for retrieval.
The LLM generates an answer grounded in retrieved chunks, often with inline citations linking back to your URL.
3.5 What AI crawlers look like in server logs
A single regex grep covers the entire current landscape. Run this against any Apache or Nginx access log to inventory AI bot traffic:
If 404 rates are above 34% for ChatGPT or Claude, your sitemap is stale or you have broken redirect chains — fixing those is a free visibility win.
Part 4: The Volume Story — Why This Matters Now
4.1 AI bots are closing in on human traffic
49–53% of internet traffic is now bots (Imperva 2025 Bad Bot Report; Thales 2026).
Cloudflare CEO Matthew Prince predicted at SXSW 2026 that AI bots will exceed human traffic by 2027.
Lumen CEO Kate Johnson stated in April 2026 that AI bots already exceed 50% of total internet traffic.
4.2 The crawl-to-refer imbalance
This is the most-cited stat in 2025–2026 GEO discourse, and it's worth dwelling on. Cloudflare publishes per-platform crawl-to-refer ratios — how many times an AI platform crawls your site relative to how many human visits it sends back:
Platform
Peak ratio (2025)
Recent ratio (mid-2025)
Anthropic
500,000 : 1 (January)
~38,000 : 1 (July)
OpenAI
3,700 : 1 (March)
~1,100 : 1 (July)
Perplexity
195 : 1
32 : 1 (News & Publications)
Google
30 : 1 (April)
9 : 1 (July)
DuckDuckGo
<1 : 1
Sends more than it crawls
Mistral
<1 : 1
Sends more than it crawls
Plain-English meaning: for every visitor an AI sends you, it crawls your site thousands of times. The economics of "crawl in exchange for traffic" that defined classic SEO no longer hold for most AI platforms — though Anthropic's ratio improved 87% after Claude added web search in March/May 2025, which is the direction the whole industry needs to move.
4.3 Per-bot volume snapshot
Vercel's crawler traffic study captures the absolute volume reality across its customer base in a single month:
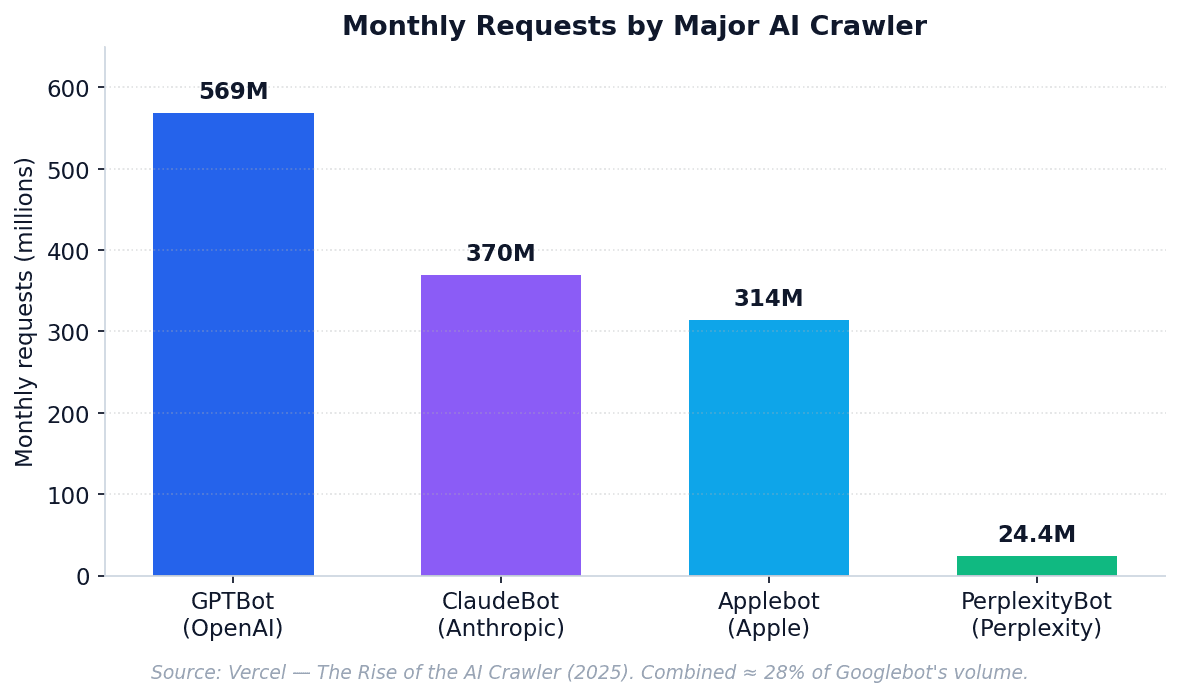
GPTBot alone generates 569M monthly requests on Vercel — roughly 12% of Googlebot's volume.
Combined, the four major AI crawlers add up to roughly 28% of Googlebot's request volume — meaning AI traffic is no longer a rounding error in your infrastructure budget. Smaller sites (under 5,000 pages) saw GPTBot alone consume 14% of total CPU in a 30-day 2026 study.
Part 5: The Compliance Crisis — Who Actually Respects robots.txt
5.1 The compliant camp
OpenAI — publishes IP ranges at openai.com/gptbot.json, searchbot.json, and chatgpt-user.json. ChatGPT Agent signs requests via Web Bot Auth.
Anthropic — publishes IP ranges via the Help Center; respects robots.txt and Crawl-delay directives.
Google, Apple, Amazon, Common Crawl, DuckAssistBot — generally compliant.
5.2 The documented violators
Perplexity — Cloudflare's August 2025 investigation "Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives" found Perplexity rotating ASNs and spoofing a Chrome-on-macOS user-agent when blocked. Cloudflare delisted Perplexity from its Verified Bots program. Reddit's October 2025 lawsuit alleged "industrial-scale, unlawful circumvention" via Google SERPs scraping — Reddit set up a hidden honeypot post that Google indexed and Perplexity surfaced within hours.
Bytespider (ByteDance / TikTok) — researchers measured Bytespider scraping at 25× the rate of GPTBot and 3,000× the rate of ClaudeBot, with no respect for robots.txt. After widespread backlash, its share of AI crawling dropped from 14.1% to 2.4% between July 2024 and July 2025.
Anthropic ClaudeBot (2024 incidents) — iFixit reported nearly one million ClaudeBot hits in 24 hours in July 2024; Linux Mint and Read the Docs reported similar episodes. Anthropic stated it respects robots.txt and the crawls stopped after iFixit added a Crawl-delay directive. Cloudflare's August 2025 stealth-crawler analysis explicitly cleared Anthropic and contrasted ChatGPT and Anthropic compliance with Perplexity's evasion.
5.3 Active lawsuits to watch
NYT v. OpenAI — motion to dismiss denied March 2025; could define the boundary between fair use and "market substitution" for AI training.
Reddit v. Perplexity, Oxylabs, SerpApi, AWMProxy — novel "data laundering" theory using Google SERPs as an indirect scraping channel.
EU AI Act (effective 2026) — requires AI providers to publicly summarize training data sources, easing rightsholders' ability to detect ingestion.
Part 6: Practical Optimization — How to Show Up in AI Answers
6.1 The Princeton GEO findings
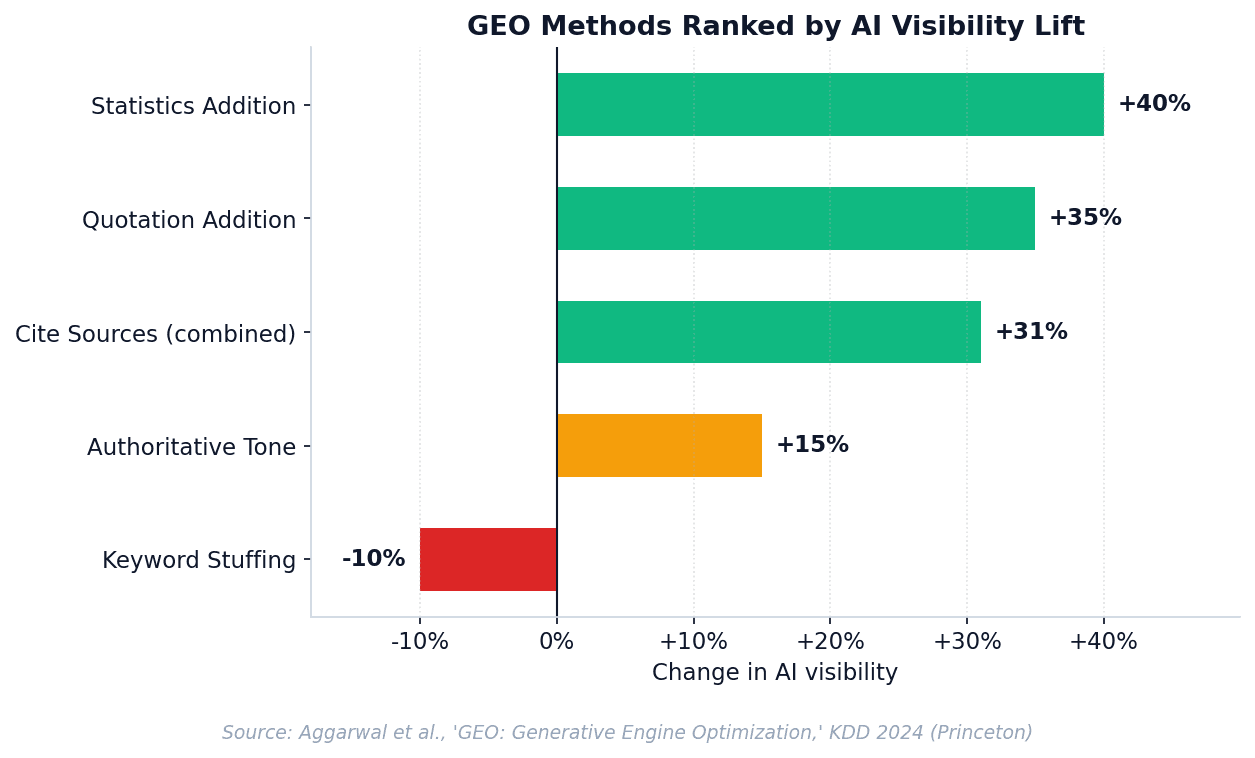
The most rigorous academic study on AI visibility — Aggarwal et al., "GEO: Generative Engine Optimization," peer-reviewed at KDD 2024 — tested nine optimization methods across a 10,000-query benchmark. Three techniques consistently produced 30–40% visibility lifts:
Statistics, citations, and quotations boost AI visibility 30–40%. Keyword stuffing actively hurts.
A subtler finding: lower-ranked pages (around position 5 in Google) saw 115% visibility improvement in AI engines after applying these methods, while position-1 pages saw little change. GEO levels the playing field for non-position-1 content — meaning sites that can't outrank an entrenched competitor on Google can still win on AI.
6.2 Server-side rendering is mandatory
View Page Source on your three highest-traffic pages right now. If your text content isn't in the initial HTML response, ChatGPT and Claude can't see it. Fixes: Next.js (SSR / ISR / SSG), Nuxt, Astro, SvelteKit, Angular Universal, or pre-rendering services like Prerender.io.
Connect entities with @id and sameAs. Match schema content to visible page content — don't cloak.
Reality check: Bing Copilot and Google AI Overviews explicitly use schema. ChatGPT, Claude, and Perplexity usage is inferred, not officially confirmed. Schema is necessary infrastructure but doesn't compensate for weak content.
6.4 Content structure best practices
Front-load. 44.2% of LLM citations come from the first 30% of a page. Strong claim-rich introductions get cited 2.1× more often.
Use bullet and numbered lists. 78% of AI answers include list formats.
Add visible "Last verified: [month year]" stamps. Pages refreshed within 90 days are 3.1× more likely to appear in AI answers (Ahrefs).
Keep FAQ answers in the 40–60 word range — the cleanest extraction window for AI engines.
Cite credible third-party sources. The Princeton study found that citing other authoritative sources increases your own citation rate.
6.5 The per-bot robots.txt recipe
A defensible "allow search, opt out of training" robots.txt — copy, customize, and deploy:
# Allow AI search & retrieval
User-agent: OAI-SearchBot
Allow: /
User-agent: ChatGPT-User
Allow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Perplexity-User
Allow: /
# Opt out of generative AI training
User-agent: Google-Extended
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: meta-externalagent
Disallow: /
Part 7: Monitoring AI Crawler Traffic on Your Site
You can't optimize what you don't measure. Here's the stack ranked by effort:
DIY (free): the regex grep above against your access logs. Pipe into wc -l for daily counts; export to CSV for trend analysis.
Cloudflare AI Crawl Control — free on all plans. Surfaces per-crawler request counts, robots.txt violations, and one-click block/allow decisions per bot.
Vercel — log drains plus middleware; Profound Agent Analytics is a one-click integration on Vercel Marketplace that parses logs and verifies user-agents against published IP ranges.
Fastly AI Bot Management — detect, block, intercept, or deceive options; integrates with TollBit for AI bot monetization.
Key metrics to track
Crawl volume per bot, per day or week
Crawl-to-refer ratio per platform — mirror Cloudflare's methodology.
Top URLs by AI bot traffic — reveals which content the AI considers authoritative.
404 rate per bot — high values signal stale sitemaps or broken redirect chains.
Training-to-retrieval ratio for each crawler family.
Part 8: What's Next — 2026–2027 Outlook
Pay-per-crawl economics. Cloudflare's HTTP 402 + crawler-price header model went live in private beta in July 2025. TollBit (with Fastly) is the publisher-side micropayment alternative. Whether AI companies pay at scale, or route around via grey-market scrapers, is the open question.
Web Bot Auth (HTTP Message Signatures, RFC 9421). Cryptographic verification displacing IP+UA. ChatGPT Agent already signs every request; expect Anthropic, Google, and Microsoft to follow. Likely IETF RFC ratification in 2026–2027.
IETF AIPREF Working Group. Standardizing AI usage preferences as a robots.txt extension. Cloudflare's Content Signals Policy (search / ai-input / ai-train) is the de facto starting point.
llms.txt. At ~0.3% adoption, with no major LLM publicly using it, this remains a low-cost speculative bet, not a confirmed signal.
Agent traffic. Both Cloudflare and Lumen publicly predict AI bots exceed human traffic by 2027.
The staged AI crawler optimization playbook: this week, next 30, next 90
The question is no longer whether to "let AI in." It's which AI bots, for what purpose, and how to structure your content so the ones that actually send traffic find and cite you. Here's the order of operations:
This week
Audit your robots.txt against the per-bot tables in Part 2. Remove deprecated tokens (Claude-Web, anthropic-ai), add explicit per-bot rules, and split decisions by category.
Run the regex grep against the past 30 days of access logs to baseline who is actually crawling.
Test SSR. View Page Source on your three highest-traffic pages. If text is missing, fix that before anything else.
Next 30 days
Implement Tier-1 schema (Organization, Article, FAQPage, HowTo) in JSON-LD. Validate with Google's Rich Results Test.