If you're trying to get your brand cited by ChatGPT, there's something important you need to know first: ChatGPT doesn't have a single, unified way of finding information. It has four fundamentally different retrieval paths, and each one operates by completely different rules.
Most SEO guides treat "ChatGPT optimization" as a monolithic problem. They're missing the point. Depending on which retrieval path is active when a user asks a question, the source selection logic, the citation behavior, and your ability to influence the outcome all change dramatically.
In this guide, we break down every retrieval path ChatGPT uses in 2026 — what triggers each one, how it selects sources, and the practical implications for your content strategy and AI visibility.
Why Retrieval Paths Matter for Marketers
Every AI system serving answers today operates with two fundamentally different memory architectures, and the boundary between them runs along a single invisible line: the training data cutoff. But in 2026, the picture is even more complex than a simple "before/after" split.
ChatGPT now serves over 200 million weekly active users, and it accounts for roughly 20% of search-related traffic worldwide as of early 2026. For businesses, the question is no longer whether AI search matters — it's whether your content is positioned to be selected by each possible retrieval mode.
The distinction between retrieval and citation is the most important thing to understand about ChatGPT optimization in 2026. An AirOps study analyzing 548,534 pages across 15,000 prompts found that ChatGPT cites only 15% of the pages it retrieves. The other 85% are pulled into the process, evaluated, and discarded without ever appearing in the answer.
That gap — between being retrieved and being cited — is where your brand either wins or disappears. Understanding which retrieval path is in play is your first step to closing it.
The 4 ChatGPT Retrieval Paths
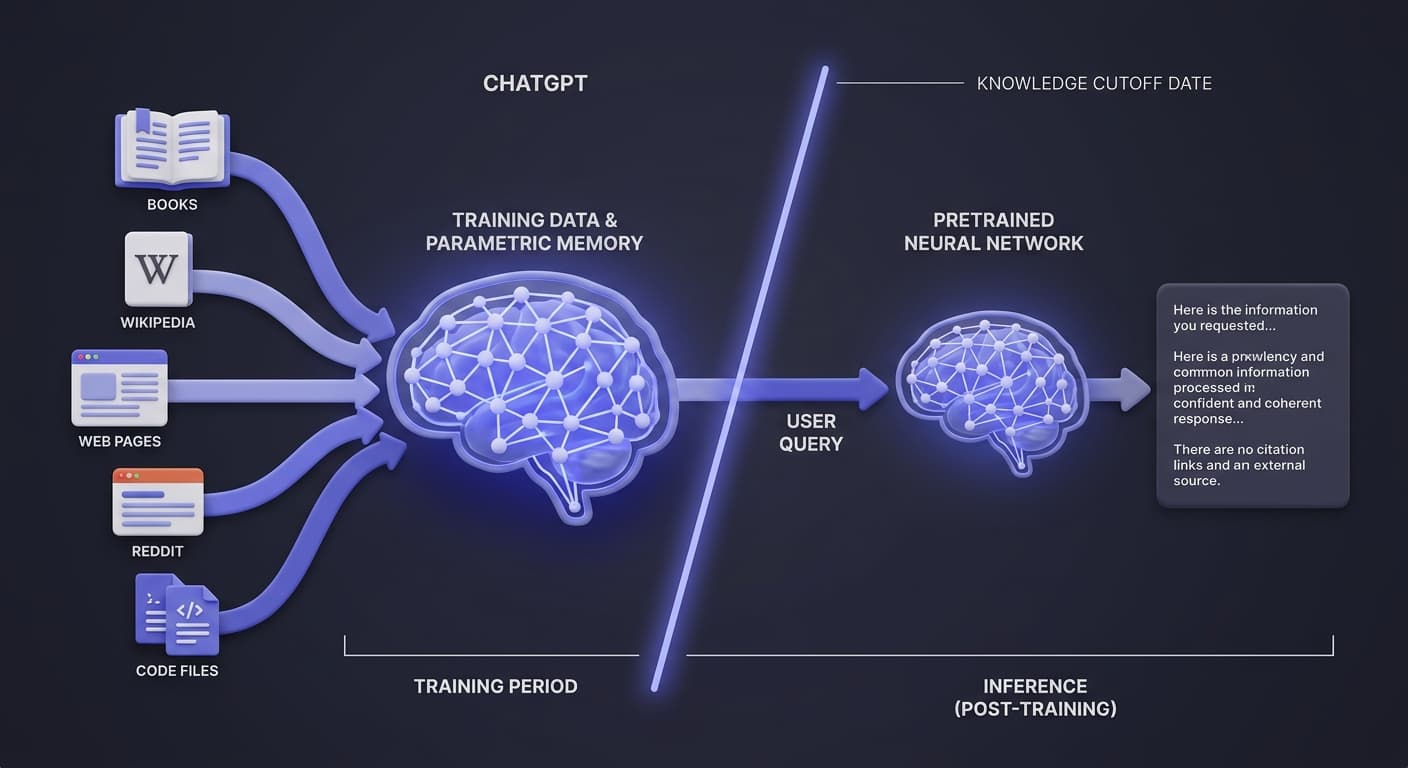
Path 1: Parametric Memory (Training Data)
Grow your organic traffic from chat-bots
Track your AI visibility across ChatGPT, Gemini, Claude, and Perplexity — and turn chat-bot mentions into traffic.
Free to start
No credit card required
Setup in 60 seconds
Try it yourself
Related free tools
Free SEO tools related to the topics covered in this article.
More articles on the same topics, prioritized by shared tags and keyword overlap.
This is the default state — and the one most users don't realize is active.
In its default mode, ChatGPT doesn't retrieve, look up, or access any external source. It generates responses entirely from parametric knowledge — statistical patterns and numerical weights absorbed during training. There are no stored documents, no URLs, and no real-time retrieval happening in the background.
Content types heavily represented in training — encyclopedic articles, popular web publications, widely shared forums — carry more weight in parametric memory than niche or low-visibility content.
ChatGPT's flagship GPT-5 series carries a knowledge cutoff of August 2025, but the older GPT-4o model, which remains widely deployed via API integrations and older interfaces, cuts off at October 2023. Web search is available in the ChatGPT interface but is selectively triggered rather than on by default for every query, meaning a substantial portion of ChatGPT responses still draw from parametric memory.
This creates a critical risk: hallucinated citations. When ChatGPT generates a response in base mode and appears to "cite" something, it isn't retrieving that source. It's constructing a plausible-sounding reference from statistical patterns — which is why fabrication rates in this mode range from 18% to 55%.
What this means for your brand:
If your brand or content was published or significantly covered before the training cutoff, it may already be embedded in the model's weights.
Content published before the training cutoff is baked into the model's weights — always accessible, confident, and unreferenced. Content published after that line only surfaces when the model retrieves it in real time, which introduces a different retrieval path, a different confidence profile, and critically different presentation behavior in synthesized answers.
Building brand presence in high-authority, widely-cited publications is your best lever for parametric visibility.
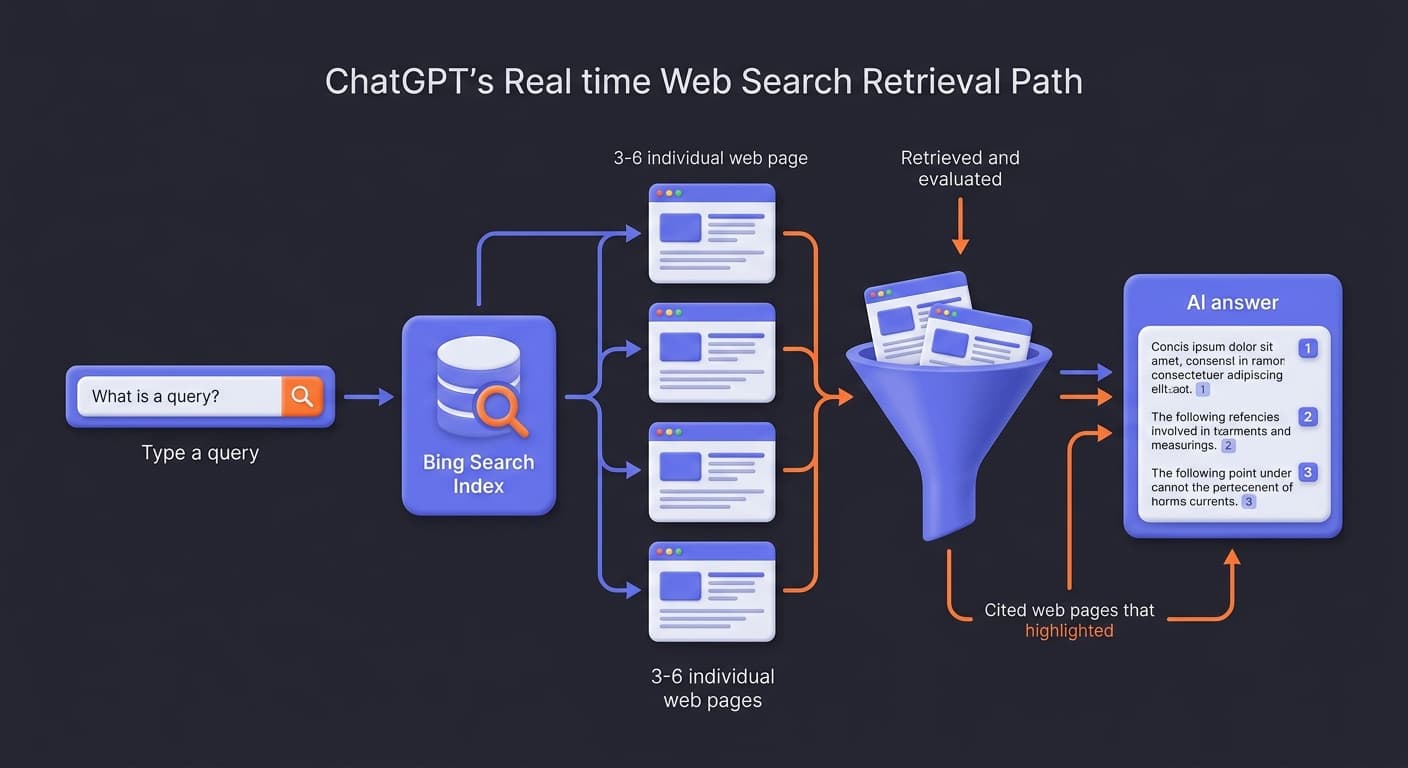
Path 2: Real-Time Web Search
When the parametric path doesn't have a confident answer — or when the query clearly involves recent events — ChatGPT switches into active web retrieval mode.
Standard browsing mode uses Bing's search index to fetch real-time results, typically returning 3 to 6 numbered, clickable citations per response. It pulls contextual snippets from open-access, non-paywalled pages and ignores restricted content.
But the model doesn't just grab whatever Bing returns and paste it in. It retrieves multiple candidate pages for a query, processes their content through its language model, and then selects which sources to cite in its synthesized answer. The selection process favours pages that present information in a format the model can extract cleanly: structured headings, direct answers positioned early, and cited claims.
This strongly suggests ChatGPT uses a hybrid retrieval architecture — drawing from multiple sources including Google results, Bing, its own web index, and potentially third-party APIs — and then applies its own re-ranking algorithm on top of the combined retrieval set.
What factors drive citation selection in web search mode?
Recent data from multiple large-scale studies in 2025–2026 paints a clear picture:
Retrieval rank is the strongest signal. Pages in the top search position were cited 58.4% of the time, versus 14.2% for pages in position 10.
Heading relevance matters. Heading relevance was the strongest on-page factor. Pages with the strongest heading-query match were cited 41.0% of the time, compared with roughly 30% for weaker matches.
Focus beats breadth. Pages between 500 and 2,000 words performed best, but pages longer than 5,000 words were cited less often than pages under 500 words.
Schema markup helps. Pages with JSON-LD markup posted a 38.5% citation rate versus 32.0% for pages without it, and articles with 4 to 10 subheadings performed best.
Domain authority is a gateway signal. Sites with over 32,000 referring domains are 3.5x more likely to be cited by ChatGPT than sites with fewer than 200 referring domains.
Freshness has a sweet spot. Pages published 30 to 89 days earlier performed best, while pages newer than 30 days performed worse. This suggests new content may need time to build retrieval signals.
There's also an important dynamic around conversation turn position. Users' opening questions trigger web searches; follow-ups rarely do. Turn 1 is 2.5× more likely to trigger citations than turn 10, and nearly 4× more likely than turn 20. If you want to be cited, you need to win the first question — the query that kicks off a research journey.
You can use tools like the ChatGPT SEO rank tracker to monitor where your brand appears in ChatGPT responses across tracked prompts — giving you a clear picture of which queries you're winning and which you're losing.
Deep Research Mode: The 100-Source Sweep
Web search also powers a more intensive mode. Deep Research is OpenAI's agent that can find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a research analyst. Powered by a version of the o3 model optimized for web browsing and data analysis, it leverages reasoning to search, interpret, and analyze massive amounts of text, images, and PDFs on the internet, pivoting as needed in reaction to information it encounters.
As of February 2026, you can now connect deep research to any MCP or app and restrict web searches to trusted sites, so you can focus on authenticated, industry-standard sources. This makes Deep Research an especially important citation surface for B2B brands — the kind of users commissioning thorough research are often the highest-value prospects.
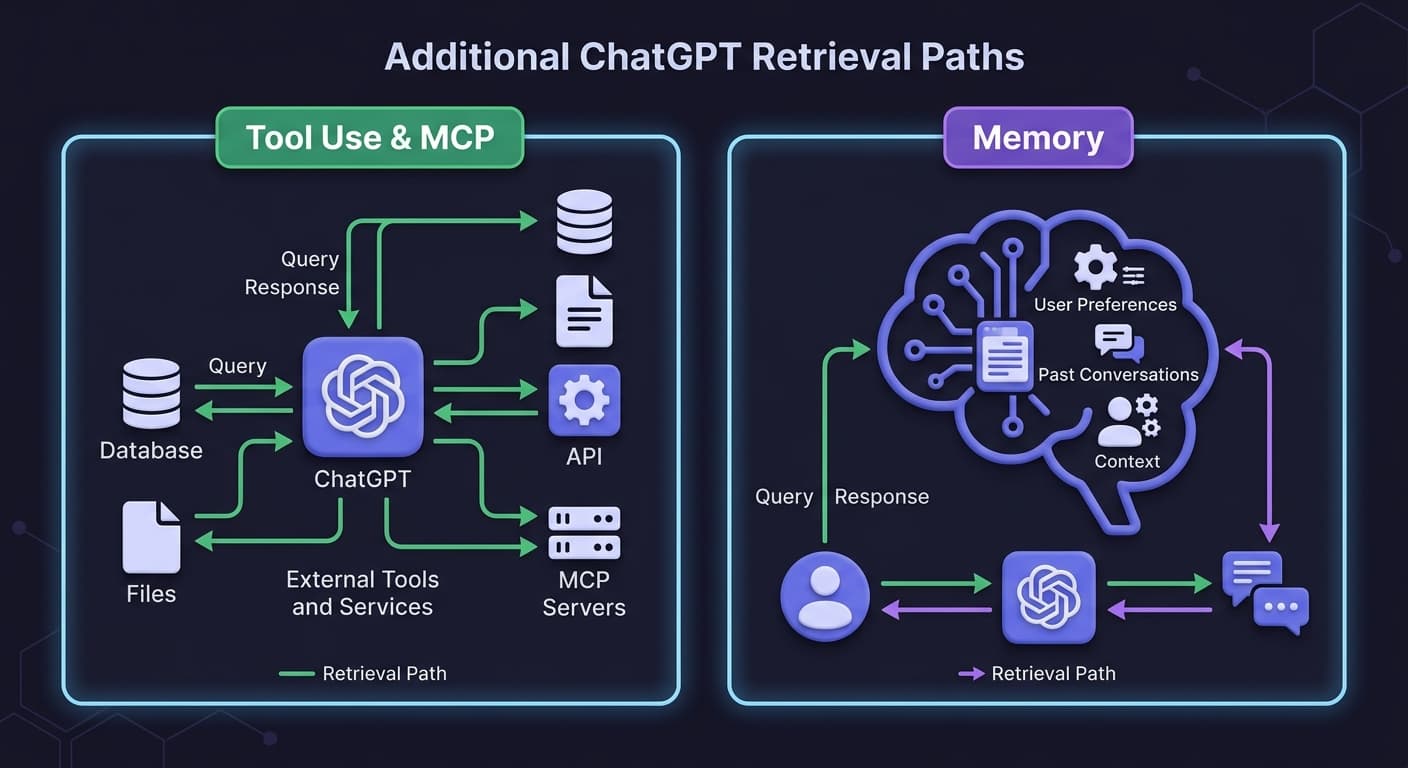
Path 3: Tool Use (File Uploads, MCP, and APIs)
The third retrieval path is the newest and most technically expansive — and it represents a fundamentally different relationship between ChatGPT and information sources.
Model Context Protocol (MCP) is an open protocol that's becoming the industry standard for extending AI models with additional tools and knowledge. Remote MCP servers can be used to connect models over the Internet to new data sources and capabilities.
OpenAI's official adoption of MCP in March 2025 across the Agents SDK, Responses API, and ChatGPT desktop app signals the protocol's importance for AI application development.
In practical terms, tool use covers a range of source access methods:
File uploads — Users upload PDFs, spreadsheets, DOCX files, or images directly into the conversation. ChatGPT extracts and processes the content as context for the session.
MCP server connections — For developers building with OpenAI's SDK, this means ChatGPT and GPT-4 can directly interact with file systems, databases, CRM platforms, and internal APIs without requiring custom integration code for each data source.
Custom GPT knowledge — Custom GPTs can be pre-loaded with specific document knowledge that becomes the primary retrieval layer for all conversations in that context.
You build the MCP server and define the tools, but ChatGPT's model chooses when to call them based on the metadata you provide. This means the model autonomously decides whether to reach out to external tools during a conversation — creating a hybrid of parametric reasoning and live data retrieval that operates largely invisibly to the end user.
What this means for your brand:
For enterprise use cases, tool-use retrieval is the dominant path for internal knowledge management.
Brands providing integrations, data feeds, or MCP-compatible APIs can essentially become a first-party data source for ChatGPT's tool-use path.
Unlike web search citations, tool-use retrieval typically doesn't surface public citations — so this path is less relevant for public brand visibility, but critical for B2B and product contexts.
Path 4: Memory (Persistent User Context)
The fourth retrieval path is the most personal — and the most recently expanded.
The Memory feature lets ChatGPT remember things you've told it — like your name, preferred writing style, or favorite topics. You can now manage this memory in settings. Memory improves with usage and is editable anytime.
In 2025, OpenAI pushed this capability significantly further. The company announced "Memory with Search," a feature that lets ChatGPT draw on memories — details from past conversations, such as your favorite foods — to inform queries when the bot searches the web.
When Memory with Search is enabled and a user types in a prompt that requires a web search, ChatGPT will rewrite that prompt into a search query that "may also leverage relevant information from memories" to "make the query better and more useful." For example, a user ChatGPT "knows" is vegan and lives in San Francisco asking "what are some restaurants near me that I'd like" may trigger the rewritten search "good vegan restaurants, San Francisco."
This is significant for two reasons:
The retrieval pool changes per user. Memory effectively personalizes the query before it even reaches the web search layer, meaning the sources ChatGPT ends up retrieving are filtered through user context.
Content strategy must address top-of-funnel queries. Because memory primarily shapes follow-up searches and personalized discovery, your content still needs to win at the first-touch, informational query stage before memory can influence repeat visibility.
The academic literature on dynamic retrieval confirms that models trigger retrieval based on initial confidence in the original question: when parametric confidence is high, retrieval often isn't triggered at all. Memory acts as an additional confidence signal — if the model has personal context about the user, it may confidently answer from that context without triggering a broader web search at all.
How the 4 Paths Work Together
In practice, these four retrieval paths don't operate in isolation. ChatGPT orchestrates them dynamically based on the query, the user's context, and the available tools. Here's a simplified decision flow:
Is the answer in parametric memory with high confidence? → Answer directly from training data (no retrieval triggered).
Does the query require recent, time-sensitive, or externally verifiable information? → Trigger web search via Bing/hybrid index; retrieve and evaluate candidate pages.
Does the user have active memory or a custom conversation context? → Incorporate personal memory to refine the search query or answer directly.
Does the conversation have active tool integrations? → Query connected MCP servers, uploaded files, or custom knowledge bases as the primary retrieval source.
What this means in practice is that your brand visibility strategy cannot treat "AI search" as a monolith. The platform your prospective buyer uses when comparing enterprise software vendors may have a completely different memory architecture than the one your marketing team tested last week.
What the 85% Problem Means for Your Content Strategy
The critical insight is that retrieval and citation are separate steps. ChatGPT retrieves far more pages than it cites. Research found that only 15% of retrieved pages earn a citation. The other 85% are read by the model but never referenced in the output.
This means there are two distinct optimization challenges you need to solve:
Challenge 1: Entering the Retrieval Pool
To be in contention for a citation, your page first needs to be retrieved. This is primarily a traditional SEO and domain authority problem:
Maintain strong backlink profiles and referring domain counts
Ensure fast page load speeds — pages with a First Contentful Paint under 0.4 seconds average 6.7 citations, whilst pages with FCP over 1.13 seconds average only 2.1 citations
Keep content fresh and regularly updated
Use the structured data validator to ensure your schema markup is correctly implemented — implementing Article schema, FAQ schema, and Author schema at a minimum gives pages with 3 or more schema types a 13% higher likelihood of being cited by LLMs
Challenge 2: Surviving the Selection Step
Once retrieved, your page competes against dozens of other sources for the actual citation:
Answer early. Every H2 section should answer its implied question within the first one to two sentences. ChatGPT reads the first 40–60 words of each section and decides whether to cite it.
Match headings to queries. The heading-query alignment signal is one of the strongest on-page citation factors in recent data.
Stay focused. A tightly scoped page answering one specific question outperforms a comprehensive guide trying to cover everything.
Build co-citation neighbors. Sources travel in packs. ChatGPT doesn't pick one winner — it cites competitors side by side. Understanding which domains are cited alongside you is critical competitive intelligence.
The AI visibility scores feature on QuickSEO tracks your brand's citation performance across ChatGPT, Claude, and Gemini — helping you understand not just whether you're being cited, but which retrieval paths are driving (or blocking) your visibility.
Which Sources Does ChatGPT Consistently Cite?
Across all web search retrieval mode activity, some source types dominate consistently:
Wikipedia — Wikipedia appears in nearly 1 in 6 conversations with citations. It's the de facto knowledge layer, the place ChatGPT goes first for baseline facts.
LinkedIn — LinkedIn's domain rank on ChatGPT moved from approximately #11 to #5 between November 2025 and February 2026, representing over a 2x increase in citation frequency. Long-form articles and LinkedIn posts are increasingly being surfaced alongside editorial sources.
Review platforms — G2, Capterra, Trustpilot, and similar platforms now function as citation sources during answer generation. LLMs retrieve from these environments because they contain structured comparisons, user feedback, and feature-level breakdowns that help answer commercial intent queries.
Domain-specific authorities — In healthcare, finance, tech, and other verticals, ChatGPT consistently co-cites the two or three dominant sources in each niche. If you're a B2B software company, the question isn't how to beat Wikipedia. It's how to become the source that appears alongside the analysts and review sites your buyers already trust.
A Practical Checklist: Optimizing Across All 4 Retrieval Paths
Here's how to align your strategy with each retrieval path:
Parametric Memory (Training)
Publish on high-authority domains that historically appear in large training datasets
Build brand mentions across Wikipedia, industry publications, and Reddit
Maintain a long-term presence — parametric visibility compounds over time
Web Search (Real-Time)
Rank in the top 5 positions for target queries in traditional search
Implement structured data markup (Article, FAQ, HowTo)
Optimize page speed (FCP under 0.4s target)
Target first-turn, informational queries — not follow-up clarifications
Tool Use (MCP & Files)
For B2B products, build or expose MCP-compatible data feeds
Ensure your content is accessible as clean, parseable text (no PDF walls or JS-heavy rendering)
For enterprise audiences, consider how your product integrates into AI agent workflows
Memory (Personalization)
Create top-of-funnel content that wins the first question in a research journey
Build brand recall through consistent messaging — if users "know" your brand, memory may route searches toward you
🚀 Track Your ChatGPT Visibility — From All Angles
Most brands are flying blind when it comes to AI search. They don't know which queries trigger citations, which retrieval path is active, or how their competitors are being mentioned alongside them. QuickSEO gives you a single dashboard to track your presence across Google Search AND AI chatbots like ChatGPT, Claude, Gemini, and Perplexity — with real AI Visibility Scores, tracked prompts, sentiment analysis, and competitor monitoring. No guesswork. No silos. Just a clear picture of where your brand stands in the AI era. Start tracking for free at quickseo.ai →
Conclusion
ChatGPT's source selection in 2026 isn't a single mechanism — it's a layered system of four distinct retrieval paths, each with its own logic, triggers, and optimization surface.
Understanding the difference between parametric memory, real-time web search, tool-use retrieval, and memory-augmented search isn't an academic exercise. It's the foundation of any credible AI visibility strategy. A brand that ranks well in web search may still be invisible in parametric memory. A brand that nails schema markup may still lose citations to a page with better heading-query alignment.
The good news: these paths can be optimized. The prerequisite is knowing which one you're operating in — and measuring your performance accordingly.
For an end-to-end look at how different AI platforms compare on source selection, take a look at our guide on AI search vs. Google Search in 2026 — the data will sharpen how you prioritize your efforts across both channels.